Easy C
06 Oct 2006この連載に目を止め,「読んでみようか」と思ってくれた皆さんは,これまで,どんなプログラム言語の経験があるでしょうか? 「JavaScriptなどのWeb系のスクリプト言語はよく使う」,「Visual BasicやJavaでアプリケーションを作っているのだけど,基本を確認したくて…」,あるいは「連載1回目だし,これからプログラミングを学びたい」など,いろいろな方がいらっしゃると思います。

本連載は,「C言語」というプログラミング言語の“定番”を通して,あらゆるプログラミングに共通する基礎となる部分を,じっくり解説していきます。初心者の方はもちろん,プログラミング経験のある方も自分の知識を再確認するのにきっと役立つと思います。
- 第1回 もう一度,C言語から始めよう
- 第2回 変数の性質を理解しよう
- 第3回 制御構文がわかればプログラムの「流れ」がわかる
- 第4回 変数のスコープをアドレスを使って理解する
- 第5回 配列を理解してアルゴリズムを考える
- 第6回 ポインタを理解して文字列を扱う
- 第7回 再帰処理と参照渡し(モドキ)のメリット・デメリット
- 第8回 構造体でデータをスッキリと扱う
- 第9回 動的なメモリーの確保とリスト処理
- 第10回 定番の関数を覚えればファイル処理などカンタンだ
- 第11回 ランダム・アクセスとバイナリ・ファイルの扱いを学ぶ
- 第12回 構造体に手足を付ければ,それがクラスだ
- コメント
第1回 もう一度,C言語から始めよう
コンピュータはマシン語しか理解しない
皆さんは,そもそもコンピュータは何語で動いているのかわかりますか? 日本人にとっての母国語が日本語で,英国人にとってのそれが英語であるように,コンピュータにとっての母国語は機械語(マシン語)です*1-1。人間は,必要に迫られれば学習し,カタコトでも他国語を話せるようになりますが,コンピュータはちっとも自発的に学習してくれません。何年たっても,マイクロプロセサが直接に解釈・実行できる言語はマシン語だけです(多くの日本人が,中学からずーっと英語を勉強しているわりに,英語を話せないという事実はまあ,それはおいといて…)。
マシン語というと,何か意味のある言葉のようなイメージがしますが,デジタル機器であるコンピュータの中では,プログラムも含め,あらゆる情報が2進数で表現されています。ですから,マシン語は人間の目には単なる数字の羅列にしか映りません。例えばこんな感じです。
4D 5A 44 01 12 00 12 00 20 00 FF …
マシン語プログラムを16進数*2で表示させると,上記のように数字が並んでいるだけなのです。
かつて,「コンパイラ」や「インタプリタ」という名前の便利な道具が存在しない時代がありました。そのころは,人間がこのマシン語でプログラムを記述していたのです。「4D5Aと書くと×××が○○○になるから,次は4401で△△△して…」と人間にとっては意味を見出せない数字の羅列でプログラムを作っていた――今,考えるとぞっとする作業ですね。
そこで,人間にわかりやすい文字で書いたものをマシン語に変換(翻訳)するプログラムが開発されました。それが「アセンブリ言語」です。アセンブリ言語では「ニーモニック」という英単語を略式化したような記号でプログラムを記述します。例えば以下のような感じです。
push ebp
mov ebp,esp
xor edx,edx
mov eax,1
…
このニーモニック・コードで記述されたプログラムを,「アセンブラ」という別のプログラムがマシン語に翻訳するのです。アセンブラは,ニーモニック・コードをマシン語に1対1で翻訳するプログラムです。ADD(加算),CMP(比較),DIV(除算),INC(+1する),DEC(-1する),JMP(無条件ジャンプ),MOV(データの転送)――といった命令が用意されています。
アセンブリ言語を使えば,数字の羅列に比べてだいぶプログラムを読み書きやすくはなりました。しかし,しょせんアセンブリ言語も,基本的にはマシン語と1対1で対応しているに過ぎません。複雑なロジックを書くには面倒だということは想像がつくでしょう。わかりやすくなったけど,プログラミングはやっぱり大変な作業であるという状態ですね。
C言語はプログラマの共通語
やがて,大規模なプログラムを,もっと効率よく,もっと簡単に作成できないかと,より自然言語*1-3に近い言葉でプログラムを記述するためのプログラミング言語(高級言語)の開発が始まりました。科学技術計算に向くFORTRAN,プログラミング初心者に適したBASIC,小数の計算が正確で事務処理に向くCOBOL,明確な文法を持つPascal――など1950年代ごろから,様々な高級言語が生まれました。
そして1970年ごろ,これから本連載で皆さんが学ぶC言語が登場したのです。C言語は当初,UNIXというOSを開発するために作られました。しかしC言語が備える機能が強力だったため,UNIX上で動作するプログラムの開発や,Windowsにも使われていくようになりました。現在,Windows用のソフトウエア開発で,C言語が一番使われているというわけではありません。それでも,現在利用されている多くのプログラミング言語は,C言語の影響を少なからず受けています。
C言語をオブジェクト指向化したC++や .NET対応のC#は当然C言語の流れをくんでいます。Javaもそうです。Webアプリケーションで使われているPerl,PHP(PHP:Hypertext Preprocessor),JavaScriptなどもC言語の影響を強く受けています。
つまりC言語をマスターすれば,プログラミングに必要な基礎が身に付くとともに,現在注目を浴びている言語を学ぶ足がかりができるのです。今のC言語は,プログラミングを深く理解するうえでの共通言語に成っているといえなくもないでしょう。
C言語はコンパイラを使う
さて,高級言語には,書いたプログラムをマシン語に翻訳するのに大きく2種類の方法,インタプリタとコンパイラがあります(図1)。図1上のインタプリタでは,プログラム実行時に1行ずつ翻訳を行います。翻訳-実行を1ステップ(1行)ごとに繰り返すわけです。実行するたびに翻訳する手間がありますから,処理速度はあまり速くはありません。でも,プログラムのバグ*1-4を見つけて修正したら,すぐに再実行できるという利点があります。短いプログラムを作成する場合や,プログラミングの学習に適しています。
 図1●インタプリタとコンパイラ
図1●インタプリタとコンパイラ
一方,図1下のコンパイラは,マシン語にプログラムを翻訳して,実行可能なファイルを作成します。プログラムに文法上の間違いがあった場合は,コンパイラがコンパイル・エラーとして出力するので,エラー・メッセージの内容を分析してプログラム上のミスを修正し,再度コンパイルしてプログラムを作っていきます。実行速度は翻訳の手間が必要ないぶんだけ,一般にインタプリタに比べて高速です。C言語は,こちらのコンパイラ方式を採用しています。
ちなみにJavaや .NETに対応したプログラミング言語(C#,Visual Basic .NETなど)も,コンパイラを利用します。ただし,これらのコンパイラは特定のOSに依存するマシン語を作成するのではなく,代わりに「中間コード」というものを出力します。出力された中間コードは,Javaなら,Java VM*1-5というJavaプログラム専用の実行環境上で,.NETなら .NET Framework上*1-6でマシン語に翻訳され実行されます。実行環境がOSの違いを吸収してくれるので,同じプログラムが別の種類のコンピュータ上でも動作できる仕組みなわけです。
なにはともあれ
コンパイラをインストールする
プログラミング言語の学習で一番大事なことは,実際に“自分の手を使って”プログラムを作成し,コンパイル・実行してみることです。読むだけではだめです。本連載でも,皆さんが実際に手を動かしながら学んでいけるようにしていきますので,どうぞ試してみてください。
本連載で利用するC言語のコンパイラは「Borland C++ Compiler 5.5」です。ボーランドがWebサイトで無償公開しています。このコンパイラを使えば,Windows 95/98/MeのMS-DOSプロンプトや,Windows XPなどのコマンドプロンプト上で,C言語あるいはC++言語で記述したソース・プログラムをコンパイルできます。
まずはインストールしましょう。今回はWindows XPにインストールする手順を説明しますが,Windows 2000や98/Meでも利用できます*1-7。インストール後に必要な設定がありますので,読み飛ばさずにゆっくりお付き合いください。
ダウンロードした「freecommandlinetools2.exe」をダブルクリックすると,インストーラが起動します。使用許諾契約のダイアログが表示されますので,同意して,インストールするフォルダを選択してください。デフォルトはc:\borland\bcc55です。特に理由がない限り,そのままがよいでしょう。インストールが終わると,c:\borland\bcc55にいろいろなファイルが作成されます。「readme.txt」というファイルに必要な設定が書いてありますので,メモ帳などのエディタで開いて読んでください。
readme.txtの「2.のa.」という欄に「既存のパスに “c:\Borland\Bcc55\bin” を追加します」とあります。パス(path)という言葉がはじめてだと,目的が理解しにくいと思いますので,簡単に解説しておきましょう。
コマンドプロンプトを起動して,カーソルが点滅している部分に次のコードを入力してEnterキーを押してください。
cd \borland\bcc55\bin
cdとは,ユーザーが作業を行うフォルダ(カレント・ディレクトリ)を移動する,MS-DOSのcd(change directory)コマンドのことです。コマンドプロンプトには「C:\cd \borland\bcc55\Bin>」という文字が出て,カーソルが点滅していると思います。つまり,カレントディレクトリが,c:\borland\bcc55\binに移動したわけです。
実はBorland C++ Compiler 5.5の本体であるコンパイラ・プログラムは,このフォルダの中にある「bcc32.exe」ファイルです。ですからここで,
bcc32
と入力すると,コンパイラ・プログラムを起動できます。でも,コンパイラ・プログラムを起動するために,いちいちc:\borland\bcc55\binにカレント・ディレクトリを移動するのは面倒ですよね。フォルダを新たに作って,そこにプログラム・ファイルを保存したいと思うでしょう。
そこでパスの設定が必要になります。というのも,c:\borland\bcc55\bin以外のほかのフォルダがカレント・ディレクトリになっている場合は,bcc32.exeがどこにあるか,Windowsが理解できなくなってしまうからです。Windowsには,「c:\Borland\Bcc55\binにbcc32.exeがあるよ」と教えてやらなければなりません。そうしないと「bcc32.exeが見つからないよ」というエラーになります。
パスを設定するには,Windows 2000/XPの場合,マイコンピュータを右クリックし,プロパティを選びます。詳細設定(Windows 2000の場合,詳細)タブを選び,環境変数ボタンを押します。続いてシステム環境変数のPathを選び,編集ボタンを押します。変数値(Windows 2000の場合,値)の末尾に,すでに入力されている文字列に続けて
;C:\borland\bcc55\Bin
と入力してください。これでOKボタンを押して登録すれば,どこのフォルダがカレントになっていても,bcc32.exeを実行できるようになります。なお,この変更は次にコマンドプロンプトを起動したときに有効になります。
もう一つやっておくことがあります。readme.txtの「2のbとc」に,「bcc32.cfgとilink32.cfgというファイルを作るように」と書いてあります。bcc32.cfgファイルの目的は,コンパイラに「インクルード・ファイル」と「ライブラリ・ファイル」というファイル群の存在する場所を指定することです。
bcc32.cfgを作らないと,コンパイルできないというわけではないのですが,作らない場合はコンパイルを行うたびに,インクルード・ファイルとライブラリ・ファイルの場所を指定しなければなりません。bcc32.cfgという設定ファイルを作っておけば,コンパイルが容易になるのです。
readme.txtの
-I”c:\Borland\Bcc55\include”
-L”c:\Borland\Bcc55\lib” という2行をコピーして,テキスト・エディタの別のウィンドウにペーストします。そしてファイル名を「bcc32.cfg」として,c:\borland\bcc55\Binフォルダに保存します。
同様に
-L”c:\Borland\Bcc55\lib”
の1行も,コピーアンドペーストして,ilink32.cfgというファイル名で同じフォルダに作成してください。
それから,c:\borlandの中に,ソース・プログラムを入れておく場所として,srcなどの名前でサブ・フォルダを作っておくとよいでしょう*1-8。これで準備はOKです。
最初のプログラムを作って実行する
さて,いよいよC言語のプログラムを書いてみましょう。
ソース・プログラムはエディタと呼ばれるソフトウエアを使って書きます。いつもお使いのエディタがあれば,それをお使いください。何もなければ,メモ帳でも構わないのですが,インターネットで「エディタ フリー」などのキーワードで検索してC言語のソース・プログラム編集に適したものをダウンロードされるとよいでしょう。
それでは最初のプログラムを書いて,コンパイル/実行してみましょう(リスト1)。画面にHelloと表示するだけのプログラムです。c:\borland\srcにエディタで作成して「hello.c」というファイル名で保存します。C言語のソース・プログラムだから拡張子はcになります。
 リスト1● 最初のC言語のプログラム。画面に 「Hello」と表示する
リスト1● 最初のC言語のプログラム。画面に 「Hello」と表示する
ここでコマンドプロンプトを起動し,カレント・ディレクトリをc:\borland\srcに移動して(前述のcdコマンドを使って),
bcc32 hello.c
と入力してコンパイルします(図2)。コンパイル・エラーがなければ,hello.exeという実行ファイルが作成されます。
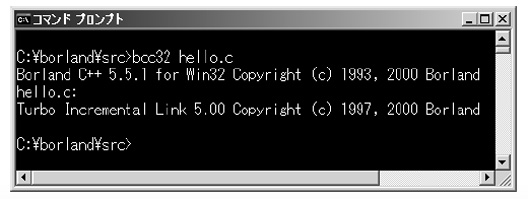 図2●リスト1のプログラム(hello.c)をコンパイルする様子
図2●リスト1のプログラム(hello.c)をコンパイルする様子
作成したプログラムを実行するには,
hello
と入力します(図3)。画面にHelloと表示されました。
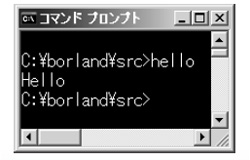 図3●コンパイルしたhello.cを実行した
図3●コンパイルしたhello.cを実行した
ここで一つ,覚えておいていただきたいことがあります。実はコンパイル処理だけで実行ファイルができるのではありません。自分の書いたソース・プログラムをコンパイラがオブジェクト・ファイル(マシン語に翻訳されている)として出力します。そのオブジェクト・ファイルを,リンカーというプログラムが,標準ライブラリとリンク(結合)して,実行ファイル(この場合ならhello.exe)を作成します(図4)。Borland C++ Compilerでは,オプションで「コンパイルのみ」を指定しない限り,エラーがなければ,自動的にリンク処理が呼び出されます。bcc32.cfg ファイルに
-L”c:\Borland\Bcc55\lib”
と記述したのは,標準ライブラリの場所を示すためだったのです。
 図4●オブジェクト・ファイルと標準ライブラリ・ファイルをリンカーがリンクして実行ファイルを生成する
図4●オブジェクト・ファイルと標準ライブラリ・ファイルをリンカーがリンクして実行ファイルを生成する
プログラムを読んでみる
連載1回目ですから,あまりややこしい話はしたくないのですが,ソース・プログラムの説明をしないわけにはいかないので,少し我慢してお付き合いください。
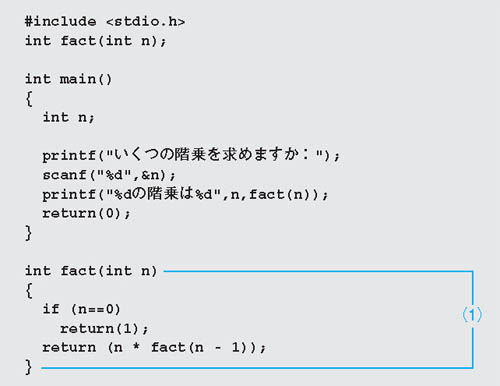
C言語は「構造型言語」と呼ばれます。アセンブリ言語のように,コードをズラズラと続くような書き方はしません。プログラムは一つ以上の複数の関数で構成されます。リスト1をもう一度見てください。
まず,mainという名前の関数(2)が必要です。関数の始めと終わりは(3)と(6)のように「{」と「}」で示します。プログラムはmain関数の1行目から実行されます。このサンプルでは(4)のprintf関数から実行されます。printf関数は「標準ライブラリ」に登録されている関数です。標準ライブラリは,画面への表示のように,プログラマの誰もがよく使う処理を集めた道具箱のようなものです。
printf関数は,ダブルクォーテーション(”)に囲まれた文字列を出力します。リンカーが標準ライブラリの一部を,自分の作ったプログラムにくっつけてくれるので,printf関数を使って画面に文字列を出力できるのです。
標準ライブラリとして,多くの関数が用意されていることがアセンブリ言語に比べて,プログラミングの効率が良い理由の一つです。C言語では,用意されている(あるいは自分で作った)関数を組み合わせて,プログラムを構成していくわけです。
ソースコードの1行はセミコロン(;)で終わります。関数は,中学校の数学の授業で習った関数と同じで,値を返します。(5)のreturn文が0という値を返しています。
(1)の「#」ではじまる命令はプリプロセッサ命令と呼ばれ,Cコンパイラがソース・プログラムを解釈する前に実行されます。#includeは<と>の中に書かれている拡張子.hのヘッダー・ファイルをインクルード(取り込み)します。stdio.hに書いてある内容が,そのまま自分のプログラムの中に展開されるのです。bcc32.cfgに記述した
-I”c\Borland
\Bcc55\include”
は,このヘッダー・ファイルのありかを示していたのです。 これで,プログラムを作成し,コンパイル,実行するまでの手順がおわかりいただけたと思います。次に,ちょっと面白いことをしてみましょう。
アセンブリ・コードと比べてみる
Cコンパイラの多くは,アセンブリ・リストを出力する機能を備えています。C言語で書いたソースコードをアセンブリ言語のコードとして出力することができるのです。例えばBorland C++ Compilerでは,次のようにオプションに「-S」を指定すると,アセンブリ・コードを出力してくれます。
bcc32 -S hello.c
なお,オプションの指定では,大文字と小文字が区別されますので注意してください。
実際に実行してみると,この例では,hello.asmというファイルが作成されます。一部を抜粋してみました(リスト2)。構成がわかりにくいかもしれませんが,セミコロンに続くコードが元のCのコードで,それ以外の部分がアセンブリ言語のコードです。
 リスト2●hello.cから生成したアセンブリ・コード
リスト2●hello.cから生成したアセンブリ・コード
なにやらズラズラと書いてありますが,コードの内容がわからなくても大丈夫です。冒頭で説明したように,ニーモニック・コードとマシン語は1対1で対応します。しかし,Cのコードとアセンブリ言語のコードは1対1にはなっていませんね。C言語のコード1行から,複数行のアセンブリ・コードが出力されています。
ソースコード1行から,複数行のアセンブリ・コード,つまりマシン語が出力されるのですから,C言語はアセンブリ言語よりもプログラムの開発効率が高いということができます。「C言語って,マシン語やアセンブラでプログラムを作るよりも便利なんだ」――そう感じてもらえれば,連載第1回の目標は達成です。
今回お話ししたテーマは,多少プログラミングに知識のある方なら,簡単過ぎる内容だったかもしれません。でもこうした基本的な部分をゆっくり,ていねいに学ぶことが,プログラミングで困ったときに対策を考えるための“よりどころ”として大きく役立つのです。
本連載では現在のプログラミング言語の基礎ともいうべきC言語を通して,プログラミングの根っこの部分の解説を「へぇー,そうなの」「なるほどね」と小さな発見をスパイスにして,お届けしたいと考えています。読み飽きない入門記事を目指して書いていきますので,どうぞよろしく!
第2回 変数の性質を理解しよう
皆さん,こんにちは。この連載「よくわかるC言語」は,今回が2回目です。前回はC言語のソース・プログラムをアセンブラのコードとして出力して,Cのソースコード1行が複数のアセンブラのコードに対応していることを確認しました。なるほどC言語は“高級”な言語なのだと,感じていただけたのではないでしょうか。
さて,皆さんがプログラミングをしていて,“こう書くとこうなるけど,その理由はわからない”という方はいらっしゃいませんか。でもあまり心配する必要はありません。なぜそうなるのかの理由がわからないのは,たぶんプログラミングがわからないのではなくて,コンピュータの動作原理などの基礎知識が不足しているだけです。今回のテーマは「変数」ですが,この“コンピュータの仕組み”に重点を置いて説明していきます。ぜひ最後まで読んでみてください。ぼんやりしていた部分がはっきりすることでしょう。
変数はメモリーの一部に名前を付けたもの
では早速始めます。変数そのものを解説する前に,プログラムが扱う様々なデータを,コンピュータがどのように“記憶”するかを確認するところからお話ししましょう。
コンピュータがデータを記憶するには,メモリーかハードディスクを利用します。メモリーは,CPUが直接アクセスできる記憶装置です。半導体素子を利用して,データを電気的に記録します。動作は高速ですが,電源を切ると内容が失われてしまいます。情報処理の用語では「主記憶装置」と呼ばれています。
電源が切れたら消えてしまうと困るようなデータを記憶させるときには,皆さんご存じのハードディスクを利用します。フロッピ・ディスクやCD-Rなどを利用することもありますね。これらは「補助記憶装置」と呼ばれています。
ちょっと当たり前すぎて簡単に感じられたかもしれません。ここからが大事なところです。補助記憶装置に記憶されたデータをコンピュータが利用するときには,必要なものだけを主記憶装置(メモリー)に読み込んで利用します。やみくもに読み込むだけでは,何がどのデータだかわかりにくくなってしまいます。なのでプログラミング言語からは,メモリーの一部を,自分が付けた名前で扱えるようになっています。これが変数です。
char型の範囲が-128~127って?
となると,変数について正しく理解しないと,目的に合った正しいプログラムを作るのは難しいですよね。変数とはどのようなものかをもう少し詳しく見ていきましょう。
変数には「型」というものがあります。型は,その変数が(1)どのような形でデータを格納するかと,(2)一つの変数がメモリーをどれくらい必要とするかの二つを定めたものと考えてください。C言語の代表的な型と表現できる値の範囲は,表1のようになります。10年いや20年ぐらい前のことですが,筆者が初めてこのような表を目にしたとき,char型は文字を表すのに,どうして-128~127って書いてあるの? と思いました。誰でも最初は素人なのです。
 表1●C言語の主な変数の型と,表現できる値の範囲
表1●C言語の主な変数の型と,表現できる値の範囲
前回,説明しましたように,コンピュータではプログラムもデータも,すべてオンとオフの2値の情報として,2進数のイメージで情報を扱います。メモリーの中に0と1がびっしり埋まっている様子を想像してください。2進数はご存じですよね。2で桁上がりする数のことです。例えば日頃使っている10進数の0,1,2,3,4を2進数で表すと0,1,10,11,100となります。この0と1の並びをどんどん,ながーく伸ばしていけば大きな値も扱えることに疑問の余地はありません*2-1。
コンピュータは,数値に限らず,文字も,音声も,画像も,2進数の0と1の並びで情報を扱います。コンピュータが生まれた国のアルファベットはもちろん,ひらがなも,漢字も,あらゆる文字も0と1の組み合わせで表現します。
複数のコンピュータで互いに情報をやりとりするためには,どの文字を,どの0と1の組み合わせで表現するかをあらかじめ決めておかなければいけません。この決まりを「文字コード」といいます。
もっとも代表的な文字コードは,ANSI(米国規格協会)が1962年に制定したASCII(アスキー)コードです*2-2。ASCIIコードでは,例えば1000001という7ビットの並び(16進数では41*2-3)がAを表し,1100001(16進数では61)はaを意味します。「1」という“文字”は0110001(16進数では31)です。表2のように,A,Bなどの可読文字だけではなく,NULやSOHなどの制御文字*2-4を含め128のコードが制定されています。
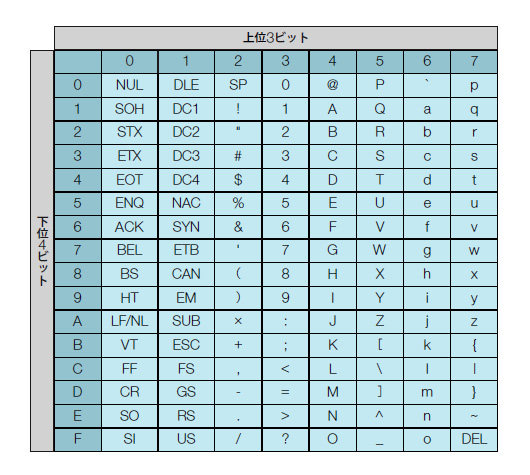 表2●ASCIIコード表。例えば「A」は上位3ビットが4,下位4ビットが1なので,コードは16進数で41とわかる
表2●ASCIIコード表。例えば「A」は上位3ビットが4,下位4ビットが1なので,コードは16進数で41とわかる
128種のコードなら7ビット,つまり1バイトで1ビットの余裕を持って表現できますよね。なので,C言語では文字は1バイトのchar型で表します。でも,漢字を含む日本語の文字は種類が多いので1バイトでは表現できません。WindowsではシフトJISコード,UNIX系OSではEUCコードなどの2バイトのコードを使って漢字やかなを表現します。また,近年では,1バイトで表現可能な文字も,漢字と同様に2バイトを使って表すUnicode(ユニコード)も広く使用されています。
説明ばかりで少し退屈してきましたね。プログラムを作って,C言語で文字を変数に代入したとき,どのように扱われているかを見てみましょう。リスト1は,変数に文字や値を代入し,様々な形で標準出力(ディスプレイ)に出力してみるプログラムです。
 リスト1●変数に文字や値を代入し,様々な形で標準出力(ディスプレイ)に出力してみる
リスト1●変数に文字や値を代入し,様々な形で標準出力(ディスプレイ)に出力してみる
実行結果は図1です。この実行結果とリスト1のコードを照らし合わせて,char型変数の中身をイメージしていきましょう。まず,リスト1の(1)でchar型の変数を四つ宣言しています。c1,c2,c3,c4という名前(識別子)で指し示すことができる1バイトの箱を,メモリーに四つ作成したと考えてください。なお,c1,c2という変数名には特に意味はありません。C言語では英字・数字・アンダースコア(_)の組み合わせを識別子として使用できます。変数に名前を付けるときは,「数字で始めることはできない」「大文字・小文字は区別される」「C言語の予約語(例えば,intやreturn)を使うことはできない」――などの規則があることを覚えておいてください。
 図1●リスト1の実行結果
図1●リスト1の実行結果
リスト1の(2)でc1に「A」という文字を代入しています。C言語では文字はシングルクォーテーション(’)で区切ります。このc1の値を画面に表示するコードは,すぐ下にある(3)のprintf関数です。printf関数は書式付きで文字列を出力します。同じ値を文字として出力したり,10進数,16進数で表示することができます。
printf関数の第1引数には文字列を指定します。文字列は,複数の文字の並びのことで,文字とは違い,ダブルクォーテーション(”)で区切ります。文字列中の%c,%x,%dなどを変換仕様といい,第2,3,4引数がこの変換仕様の部分に展開されていきます。文字として出力するには%cを,16進数として出力したい場合は%xを,10進数の整数として出力する場合は%dを指定します。第2,3,4引数はどれもc1です。図1の実行結果を見ると,
文字:A 16進数:41 10進数:65
と表示されていますね。文字としては「A」なのですが,メモリー内部では16進数で41,つまり2進数で01000001というビットの並びで表現されていることがわかります。
さて,printf文の第1引数で指定した文字列の中に,画面に表示されていない文字があります。「\n」です。\nは改行を意味する「エスケープ・シーケンス」です。エスケープ・シーケンスは,画面に表示できる文字だけで,制御文字を入力するための仕組みです。\nのように,「\」と「n」を続けて入力すると改行の制御文字を表すことができます。なのでリスト1の(3)の実行を終えたところで,1行改行しているわけです。なお,「\」という文字そのものを表したい場合は,「\」と\を二つ続けて入力します。
(4)の\x61も,2桁の16進数で61を表すエスケープ・シーケンスです。(5)で文字として表示させると,aと表示されます。(6)と(7)は文字としての「1」の表示です。文字の1は,16進数で31,2進数で00110001というビットの並びです。
(8)と(9)は変数c4に代入した\nを文字として出力しています。図1を見ると,「\n」と表示される代わりに,行が変わっていますね。改行を意味する制御文字を表示しようとすると,画面では改行として扱われます。\nは16進数ではa,10進数では10と表示されています。2進数では00001010です。
足し算で小文字を大文字に変える
一つの英数字が,メモリー上では2進数8桁で表されているというイメージをつかむことができたでしょうか。次に,キーボードから入力した英字の大文字を小文字に変換するプログラムを考えてみましょう。
英字の大文字はA=41(16進)からZ=5A(16進)まで,順序よく並んでいます。小文字もa=61(16進)から,お行儀よく整列しています。char型の変数といっても中味は数値ですから,文字と文字を足し算したり,引き算したりと,お互いに計算させることができます。Aとaの数値としての差と,Zとzのそれに違いはないので,入力された大文字に’a’-’A’の値を足してやれば,小文字になるはずです。
この仕組みをプログラムとして書いたのがリスト2です。(1)で宣言したchar型変数cに,(3)のscanf関数で文字を入力しています。
scanf(“%c”,&c);
の「%c」はprintf関数に指定したものと同じ変換仕様です。標準入力(キーボード)から文字を1文字読み込みます。
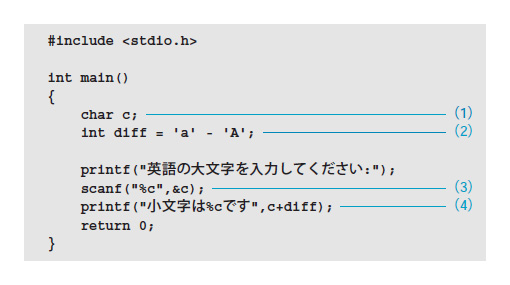 リスト2●大文字を小文字に変換する
リスト2●大文字を小文字に変換する
第2引数にある「&c」の「&」はアドレス演算子といい,指定した変数のメモリー上の場所(アドレス)を取得します。変数のアドレスについては,今後の連載でじっくりと説明しますが,scanf関数は変数という一つの箱に値を入れるときに,変数の名前ではなく,“場所を教えてくれ”と要求する関数なのだと理解してください。ともかくこのように書くと,char型の変数cに文字を読み込むことができます。
さて,aとAの差は,リスト2の(2)でint型(整数型)の変数diffに入れています。int型は4バイトで整数を記憶するデータ型です。整数値として差異を求めることが目的なので,char型ではなくint型を使用しています。(2)のように変数は宣言と同時に値を代入し,初期化することができます。(4)では,入力された文字にdiffを足して小文字に変換しています。
実行結果は図2です。「J」が「j」に変換されていますね。なお,このサンプル・プログラムでは,入力された値のチェックを行っていません。実用的なプログラムにするには,入力値が英字大文字の範囲内にあるかどうかをチェックする必要があります。
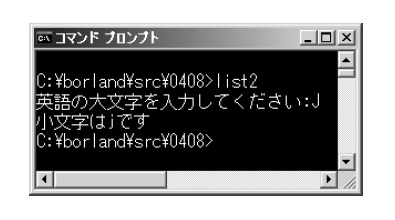 図2●リスト2の実行結果
図2●リスト2の実行結果
コンピュータは小数点以下の計算が苦手?
ここまでは,char型(文字型)とint型(整数型)の変数を使ってきました。それぞれunsignedと付いている型は符号なしで正の値のみを扱うための型です。各変数のサイズはコンパイラやOSの種類によって異なる場合がありますが,Borland C++コンパイラで作成したプログラムは,int型は4バイト,char型は1バイトのメモリー領域を使用します。
整数型には収まらないような大きな値や,小数点以下の値を含む実数を扱うときに,C言語ではfloatやdoubleといった浮動小数点数型を使います。科学技術計算などでよく用いられ,実際とても便利なのですが,計算すると誤差が出る場合があり注意が必要です。
サンプル・プログラムで見てみましょう(リスト3)。0.2をfloat型の変数に111回足して,その値が22.2と等しいかどうかを調べ,等しい場合は「0.2を111回足すと,22.2になります。」と表示するものです。
 リスト3●浮動小数点数型の変数に0.2を111回足して,結果が22.2になるかを試す
リスト3●浮動小数点数型の変数に0.2を111回足して,結果が22.2になるかを試す
リスト3を読むためには,「++」など,C言語特有の演算子と制御文を理解する必要があります。リスト3の内容に入る前に簡単に解説しておきましょう。リスト3の(2)で登場する「++」は,インクリメント演算子と呼びます。「i++」と書くと,iに1を加算します。Visual Basicなどでは単純にカウンタの値を1アップさせるときでも,i = i + 1と書かなくてはならないので,「C言語みたいにi++と書ければ良いのに」と筆者は面倒に感じます。減算はデクリメント演算子を使ってi–と書きます。
なお,インクリメント演算子とデクリメント演算子は,++iのように変数の前に記述することもできます。変数を単純にインクリメント,デクリメントするだけなら,演算子を前に置く(前置)場合と後ろに置く場合(後置)に違いはありません。でも,式の中で使う場合は注意が必要です。
例えば,aが0のとき,後置インクリメントで
b = a++;
を行うと,aの値は1になりますがbの値は0です。
b = ++a;
と前置にするとaとbの両方が1になります。後置では,bにaを代入してからaをインクリメントし,前置ではaをインクリメントしてからbに代入するという違いがあるのです。
ほかに,C言語で利用する主な演算子を表3にまとめておいたので参照してください。制御文の書き方は,コードを追いながら解説しましょう。
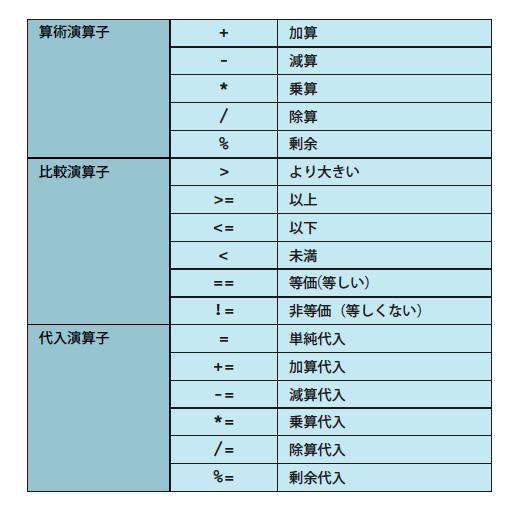 表3●C言語の主な演算子
表3●C言語の主な演算子
というところで,リスト3の解説に入ります。(1)でfloat型の変数fを宣言すると同時に,0を代入して初期化を行っています。(2)のfor文が0.2を111回繰り返し加算する制御文です。forのカッコの中にある「i=0;i<111;i++」は,iが0から111より小さい間,一つずつiの値を増やしながら繰り返しをする,という意味です。なので,iが0から110まで順番に,(3)の文を繰り返し実行します。
(3)のf+=0.2もC言語の便利な書き方で,意味は上の行にコメント*2-5として記述してあるように,f = f + 0.2です。もちろんf = f + 0.2と書くこともできます。減算や掛算,割り算も同様に,-=,*=,/=と記述することができます。くだくだ書かなくてもよいところが,C言語がプログラマに好まれる理由の一つかもしれません。
0.2を111回足した値が22.2と等しいかどうかを判断しているのが(4)のif文です。if文は条件分岐を行う制御文です。この例ではelseとともに記述していますので,fが22.2と等しいとき(5)の文を実行,else(それ以外)のとき(6)を実行します。==は等しいかどうか比較する演算子です。比較演算子はほかにも表3のように用意されています。
さて,このプログラムの結果はどうなるでしょうか? 意外かもしれませんが,「0.2を111回足しても,22.2になりません。」と表示されるのです(図3)。何度実行しても22.2にはなりません。「0.2を111回足せば,22.2に決まっているじゃないか!」と普通,思いますよね。でも浮動小数点数型の計算では,小さな違いが出てしまうのです。
 図3●リスト3の実行結果
図3●リスト3の実行結果
皆さんは,1÷3が割り切れず,0.3333…という「循環小数」になることはご存じですよね。0.3333…を3回足しても1にはなりませんね。一方,1÷2は0.5ぴったりの「有限小数」です。
今回リスト3で利用した0.2は,私たちになじみの深い10進数では有限小数ですが,実はコンピュータにとっては循環小数なのです。コンピュータの中ではあらゆる情報が2進数で扱われています。10進数ではきりのよい数値が,2進数では扱いにくい数になることがあるのです。2進数になじみがないとイメージしにくいかもしれません。あわてず,ゆっくり考えていきましょう。
10進数の9999は,10の0乗×9 + 10の1乗×9 + 10の2乗×9 + 10の3乗×9と表すことができます。同様に,2進数の1011は2の0乗×1 + 2の1乗×1 + 2の2乗×0 + 2の3乗×1と表すことができます。
10進数では桁上がりすると,10倍,100倍…となっていきます。一方,2進数の場合は2倍,4倍…です。では,小数点以下はどうなるのかと言うと,10進数では,1/10,1/100…ですから,2進数では,1/2,1/4…と半分,半分になっていくのです。ここで,10進数の0.2を2進数で表すために2進数の各桁の値を足していくと,0.001100110011…と,0011を繰り返す循環小数になってしまいます。
このように,10進数では有限小数だった数が,2進数では循環小数になってしまうことがあるのです。というわけで浮動小数点数型を使うときは,乱暴な言い方に聞こえるかもしれませんが,「近似値を求めるのだ」と最初から割り切っておくことが必要でしょう。金属の金は,フォーナイン(999.9)で純金ですし,工業や科学技術計算では許容できる誤差があります。例えば,このサンプル・プログラムの場合,完全に一致していなくても,22.2との差が0.0001未満なら一致していると判断してもいい場合があるのです。しかし,どうしても困る分野もあります。銀行の金利計算や為替の計算では,近似値というわけにはいきません。コンピュータの都合で,誰かが損をすると困ってしまいます。
そのために,例えばVisual Basicには通貨型(Currency)が用意されていたり,データベースにもMoney型などの正確に金額を記憶するための型があるのです。また,事務処理分野で古くから利用されてきたCOBOL言語には,BCD(Binary Coded Decimal:2進化10進数)という形式があります。BCDでは10進数の0から9までを,4桁の2進数で表現します。185は,1と8と5をそれぞれ,0001,1000,0101と表すことができます。これに小数点が何桁目の位置にあるかという情報があれば,人間と同じように10進数で計算することができるのです。
では,そういうデータ型が用意されていないC言語ではどうすればよいのかと言うと,計算は整数で行い,計算結果を小数点以下の値を含む値に戻すという方法が考えられます。0.2を111回足した結果を表示するのなら,2を111回足して,最後に10で割って答えを出すようにすればいいのです。
いかがでしたか? チマチマした話しばかりでちょっと面白くなかったかもしれませんね。コンピュータってやつは案外,頼りない機械で,ソフトウエアとして人間の知恵を大量に投入することで初めて正しく性能を発揮できるのだということを感じていただけたら,連載2回目の目標は達成です。次回からは,もう少しプログラムらしいプログラムを作成していきます。ぜひ,お読みください。
■変更履歴
本文で『C言語の予約語(例えば,mainやreturn)を使うことはできない』としていましたが,mainは予約語ではありません。お詫びして訂正します。本文は修正済みです。 [2007/06/07 17:40]
第3回 制御構文がわかればプログラムの「流れ」がわかる
「よくわかるC言語」,今回は連載3回目です。1回目はBorland C++コンパイラ*3-1のオプションを指定して,C言語のコードの1行から複数のアセンブリ・コード,つまりマシン語が出力されることを確認しました。2回目は浮動小数点数の計算に誤差が出る理由などを説明し,変数の性質を学びました。さて今回は,プログラムの構造を説明し,「C言語のプログラムはどのように書けばよいのか」を大まかに理解してもらうことを目標にします。カメラのズームをいったんぐっーと引くように,ワイドな視界でC言語のプログラミングを眺めてみましょう。
基本は構造化プログラミングにあり
皆さんは「構造化プログラミング」という言葉をご存知ですか? 1960年代後半,エドガー・ダイクストラ*3-2が中心となって提唱したプログラミングの考え方です。現在,主流となりつつあるオブジェクト指向プログラミングも,実は構造化プログラミングをベースとしています。
構造化プログラミングの目的は,大規模なプログラムを効率よく作成し,プログラムのミス(バグ)を少なくすることです。そのための具体的な方法としてダイクストラは,プログラムに必要な手続きをいくつかの単位に分け,メインの処理に大まかな処理を,サブルーチンに細部の処理を記述せよと主張しました。また,プログラムは「順次」「反復」「分岐」の三つの基本構造で記述できるという構造化定理を証明し,結果として「goto文は不要である」と主張しました。
「goto文は不要」と言われても,goto文自体を見たことがない方もいるでしょう。goto文というのは,プログラムの途中で,指定した行番号やラベルにジャンプできる制御文のことです。例えばgoto文を実装している初期のBASIC言語で書かれたプログラムは,goto文でプログラム中の行番号やラベルに飛んで,そこに記述してある処理を数行実行したあと,またgoto文でどこかへ飛んでいく――という構造になっていることが多かったのです(図1)。これでは,どこから来てどこへ行くのかわからないスーパーマンのようなもので,いつどのコードが実行されるのか,ロジックを追うことが難しくなります。「実行直前に他の場所に飛んでしまうので,永遠に実行されないコードがあった」なんてことも古いプログラムではよくあったのです。
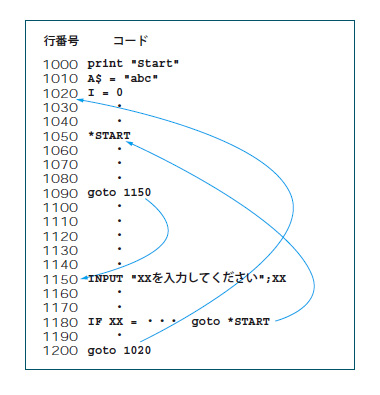 図1●BASICにおけるgoto文のイメージ
図1●BASICにおけるgoto文のイメージ
そういった複雑さを読み解くことに,迷路やクイズのような楽しさを感じる方がいらっしゃるかもしれませんが,一般的に「わかりにくい」プログラムほど「迷惑」な話はありません。そこで以降は,ダイクストラの教えに従って,C言語で,
●プログラムを複数の単位に分けて作成する ●順次・反復・分岐の論理構造を作る
方法を解説していきましょう。
関数という単位で複数の単位に分ける
C言語は,printf関数*3-3を始めとする汎用性の高い関数をライブラリ関数として標準で装備しています。しかし,装備している関数を使うだけで,すべてのプログラムを作成できるわけではありません。
リスト1のCのプログラムを見てください。文字型の変数cに「文字」として0から9までの数字を代入し,printf関数に%c ,%xと変換仕様を指定して,文字と16進数を画面表示させるプログラムです(図2)。文法上は何の問題もありません。でも,何か冗長な感じがしませんか?先の構造化定理の中で,使っているのは「順次」,すなわちmain関数の上から下に向かって処理が実行されている部分だけですね。
 リスト1●0から9までの「文字」と,その16進数を表示するプログラム。文字が増えればコードは長くなり,冗長である
リスト1●0から9までの「文字」と,その16進数を表示するプログラム。文字が増えればコードは長くなり,冗長である
 図2●リスト1を実行した結果
図2●リスト1を実行した結果
これをリスト2のように書き直してみるとどうでしょう? outxという名前の自作の関数を作り(1),main関数から呼び出すようにしてみました(2)。main関数の内部では,繰り返しを行う制御文for(後述)を使って,変数cの値が文字としての‘0’から‘9’以下の間,処理を継続させています。
 リスト2●リスト1を関数という単位で作り直したCのプログラム
リスト2●リスト1を関数という単位で作り直したCのプログラム
リスト2のポイントは,
●main関数が処理の制御を行っている ●outx関数が画面への値の出力を行っている
の2点です。main関数とoutx関数の二つだけですが,プログラムを複数の単位に分けたわけです。
このような「関数化」のメリットは何でしょう。まず「コードの量が少なくなる」という点が挙げられます。コードの量が多ければ多いほど,タイプミスなどが原因でバグが出やすくなりますから,関数化すれば間違える確率が下がります。リスト1のように「printf(“%c:%x “,c,c);」を何度も書くより,「outx(c);」を1行だけ書く方が,間違えにくいですよね。
また,処理を関数としてうまく分割してやることで「プログラムがわかりやすくなる」ことも挙げられます。「この関数ではXXXの処理を行う」とシンプルなコメントで説明できる関数を作れば,メンテナンスも容易になるでしょう。
それでもまだメリットを実感できない方は,main関数に500~600行とコードがズラズラ記述してあるプログラムをイメージしてください。筆者ならとてもそんなコードを読みたくありません。小さなプログラムなら,1人暮らし用の小さなワンルーム・マンションのように,トイレと風呂で一つの部屋(関数),それ以外で一つの部屋,で済むこともあるでしょう。しかし家を建てる時に1階を全部ワンルームにして,キッチンも子供部屋も客間も寝室も,あろうことかトイレもバスも仕切りなしに,ぜーんぶ1部屋に収めたら,メチャクチャになりますよね。たくさんの家族が住む2世帯,3世帯住宅のような大きなプログラムだと,それに応じた部屋数(関数)が必要になることは,十分納得いただけると思います。
とはいえ,どの部分を関数として作成するかの判断には,ある程度のプログラミング経験が必要です。初心者の方は,最初のうちは目的の処理をザッーと書いて,そのあとで同じような処理を書いてあるコードを見つけて関数にしていけばいいでしょう。それだけでも,ずっと「わかりやすい」良いプログラムになるはずです。
C言語の関数は値渡しがデフォルト
関数の話題が出てきたので,せっかくですからC言語の関数の仕組みをもう少し掘り下げておきましょう。
関数には値を受け取って処理を行い,その結果の値を返す仕組みが用意されています。リスト2では,main関数の前に「int」と書いてありますね。これは「型宣言」で,main関数がint型の関数であること,つまりint型の値を返すことを表しています。型について忘れてしまった方は,前回の本連載を読み返してください。
main関数の最後で「return 0」とあるのは,return文で0を返すという意味です。C言語では,プログラムが正常終了した場合に「0」を返し,そうでない場合は違う値を返すようにプログラミングすることが多いのです。
outx関数の型はvoidとなっていますね。voidは,この関数が値を返さないことを表します。Visual Basicプログラマの方なら,Subプロシジャのようなものだと思えばいいでしょう。
関数の間で値を受け渡しする仕組みで重要になるのが,引数(ひきすう)です。引数には仮引数(かりひきすう)と実引数(じつひきすう)があります。リスト2で言えば,outx関数を定義した「void outx(char c)」の「char c」が仮引数で,main関数の「outx(c);」の「c」が実引数となります。つまり,関数を定義するときに指定する値が仮引数,関数を実際に呼び出す際に指定する値が実引数というわけです。
ここで大事なことが一つ。C言語では,引数は値渡し(pass by value)で渡されるということです。変数である実引数そのものが,関数に渡されるのではなく,引数に指定した変数の「値」が関数に渡っていくのです。変数そのものが渡されるのと,変数の値が渡されることにどんな違いがあるのか,具体的に説明しましょう。
リスト3のプログラムを見てください。kake関数を独自に定義し,main関数からkake関数を呼び出すプログラムです。main関数では変数aに3を,bに5を代入してkake関数を呼び出し,kake関数はaとbの値を受け取って,掛け算した結果をint型で返します。ポイントは,kake関数の中でaを2倍しているところです(1)。main関数の「printf(“%d X %d = %d \n”,a,b,c);」では,最初にaの値を,次にbの値を,最後にaとbを掛けた値cを表示するわけですから,「6 × 5 = 15」と表示しそうなものですよね。しかし,実行結果は図3のように「3 × 5 = 15」となるのです。kake関数側で受け取ったaを2倍しても,main関数側のaには何も影響がありません。これはいったい,どう考えればいいでしょうか?
 リスト3●C言語の値渡しを確認するためのプログラム
リスト3●C言語の値渡しを確認するためのプログラム
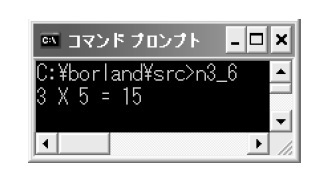 図3●リスト3を実行した結果
図3●リスト3を実行した結果
話は簡単です。要するに,kake関数に変数aとbのコピーが渡されたのだと思えばいいのです。コピーの値を変更しても,コピー元には何も影響はありませんよね。例えば,ワープロソフトで作成したドキュメントをネットワーク経由で他のパソコンにコピーして編集しても,コピー元のファイルには影響がないのと同じ理屈です。
こんな風に書くと,これが当たり前のように感じられるかもしれませんが,ほかのプログラミング言語,例えばVisual Basic 6.0はC言語とまったく逆です。キーワードByValを記述して,明示的に値渡しであることを宣言しないと,main関数側のaの値も変わってしまうのです。これを参照渡し(pass by reference)と呼びます*3-4。この値渡しの仕組みによって,C言語では関数の独立性が高くなっています。これらの関係をまとめると図4のようになります。
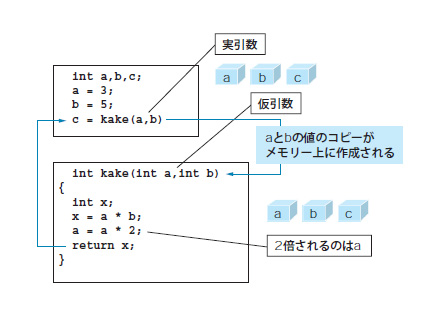 図4●仮引数と実引数のイメージ
図4●仮引数と実引数のイメージ
for,while,if,switchで反復と分岐を実現する
さて,ダイクストラの「処理を分割する」教えがある程度理解できたところで,今度は「順次・反復・分岐の論理構造を作る」方法について説明しましょう。
C言語では,決まった回数,処理を反復させるために「for文」を使います。また,ある条件が成り立つ間,処理を反復させるためには「while文」を使います。それぞれのコードの例とプログラムの流れを図示すると図5のようになります。for文には,反復処理を行うための初期値である式1,反復すべきかどうかを評価する式2,反復回数をカウントする式3の三つのパラメータが必要ですが,while文では条件式が一つあればいいことがよくわかると思います。
{kind=link}
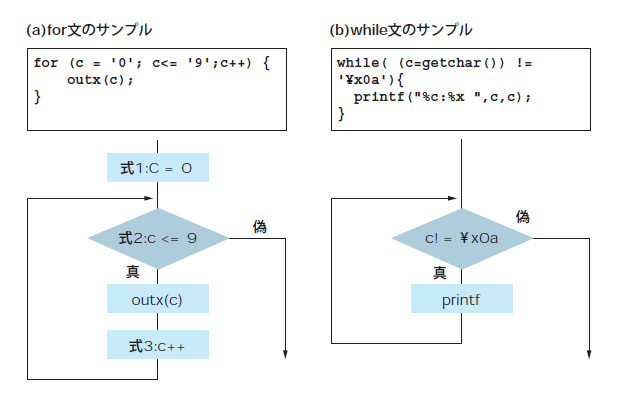 図5●for文とwhile文を使ったC言語のプログラムと流れ
図5●for文とwhile文を使ったC言語のプログラムと流れ
ちなみにC言語には,for文やwhile文のほか,do~while文という制御文もあります。while文はループを開始する前に条件をチェックするのに対し,do~while文はループ中の処理を一度実行してから,続けて処理を行うかどうか条件を判断します。
では,実際にfor文を使ったサンプル・プログラムを見てみましょう。乱数の値によって「大当たり!」と表示するプログラムです(リスト4)。大きくmain関数とran10関数の二つの関数に分かれ,main関数の中でfor文を使って1から10までの値aをランダムに計算しています。条件式から10回反復することがわかると思います。
 リスト4●for文とif文を使ったプログラム
リスト4●for文とif文を使ったプログラム
(1)のrandは,乱数を返す関数です。乱数の範囲は0から定数RAND_MAX以下の値になります。RAND_MAXはプリプロセッサ命令#includeでインクルードしているstdlib.hの中に定義されています。
ran10関数は乱数発生プログラムとでも言うべきもので,
return rand()%10 + 1;
で剰余演算子%を使い,rand関数が返した乱数を10で割った余りを求め,1を足しています。こうすると,1から10の範囲でランダムな数を得ることができます。
main関数の
srand((unsigned) time(NULL));
は,乱数の種(seed)を与えるものです。time関数はグリニッチ標準時(GMT)の1970年1月1日00:00:00 から現在までの経過時間を秒単位で表した値を返します。「種って何?」と言われそうですが,要するに乱数を計算するための素です。rand関数を使う前にsrand関数を実行しないと,同じ数ばかりがrand関数から返されてしまうのです。理屈で考えるよりも,やってみれば明白なので,リスト4のsrandの行を/と/ではさんで,コメントにして実行してみてください。同じ数ばかりが表示されるはずです
C言語でもgoto文は使えるがエラー処理に限定すべき ダイクストラによって「不要である」と言われてしまったgoto文ですが,実はC言語でも,goto文を使うことができます。ラベルとgoto文を使って反復するプログラムを見てみましょう。
>リストAのコードを入力してファイルを作成し,実行してみてください。1から10までの数値が表示されます(>図A)。goto文を使ってloopとendというラベルにジャンプさせ,あたかもfor文のような反復処理を実現しているわけです。
しかしこのコードを見て,特にメリットを感じるところがありますか? 筆者からすれば,for文を使ってループさせた方が,よっぽど簡潔に見えます。
goto文とラベルは,特定の処理,例えば処理の途中でエラーが発生したときに,エラー処理に飛ばすといった使い方に限定した方が良いでしょう。
 リストA●C言語でgoto文を使ったコード
リストA●C言語でgoto文を使ったコード
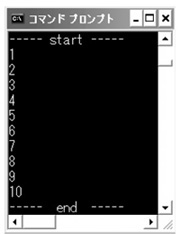 図A●リストAを実行した結果
図A●リストAを実行した結果
リスト4には,反復だけでなく,分岐の構文も登場しています。「if文」です。if文を使って,aの値が10と等しいかどうかを評価し「真」ならば「大当たり!」と表示させています(図6)。「これではあまりにシンプルすぎる。評価の結果で偽となったとき,別の処理を行わせたい」ということならば,「if~else文」を使えばいいでしょう。リスト4の(2)の部分をリスト5のように,if~else文に置き換えて実行した結果が図7です。
 図6●リスト4を実行した結果。コンパイル時に警告が出るがプログラムは実行可能
図6●リスト4を実行した結果。コンパイル時に警告が出るがプログラムは実行可能
 リスト5●リスト4の(2)の部分をif~else文に変更したコード
リスト5●リスト4の(2)の部分をif~else文に変更したコード
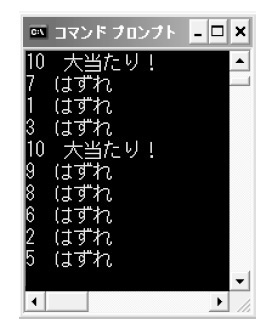 図7●リスト5の変更を加えて実行した結果
図7●リスト5の変更を加えて実行した結果
分岐は,if文やif~else文だけではありません。一つの式が返す値によって何種類も分岐を作りたいときは「switch文」を使います。リスト6は,今日の運勢を占うプログラムです。リスト4のran10関数のロジックをそのまま使って乱数を発生させ,その値によって出力するメッセージを変えています(図8)。乱数aの値が1だと「最高!」,2だと「いいですよ!」と表示します。乱数が1,2,9,10のいずれでもないときは,default以下が実行され,「ぼちぼちかな」と表示します。このようにswitch文を使うと,複数の分岐をすっきりと表現することができます。
 リスト6●switch文を使ったプログラム
リスト6●switch文を使ったプログラム
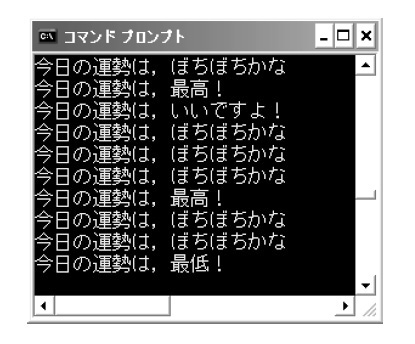 図8●リスト6を実行した結果。コンパイル時に警告が出るがプログラムは実行可能
図8●リスト6を実行した結果。コンパイル時に警告が出るがプログラムは実行可能
switch文で注意してほしいのは,break文の存在です。条件に一致して,該当のメッセージを出力した後のbreak文を書き忘れると,次のcase文に記述された処理まで実行されてしまうからです。他のプログラム言語では,break文が不要な場合があるので,筆者もついつい忘れてしまいがちです。皆さんも気をつけてください。
関数の順番を意識させないプロトタイプ宣言
さて,main関数のほかに,もう一つの関数を持つプログラムをいくつか見てきました。これらのリストを見て,何か気が付いた点はありませんか? それは,もう一つの関数が,必ず“main関数の前に”書かれていた点です。プログラムを上から順番に読んでいくことを考えると,いつまでもmain関数が出てこないことにイライラした方もいるでしょう。さらに言えば,(これまであえて説明しませんでしたが)リスト4~6まで,コンパイルすると出力される警告メッセージ「W8065~プロトタイプ宣言のない関数~」が気になっていた方もいらっしゃるかもしれません。
では,関数の順番を入れ替えれば警告が出なくなるのでしょうか。実際にリスト2のプログラムの関数の順序を入れ替えて,main関数の下にoutx関数を持っていきましょう。先ほど作った実行ファイル(拡張子exe)を削除してからコンパイルすると,「** 1 errors in Compile **」と今度はコンパイル・エラーが表示され,実行ファイルそのものが作成されなくなってしまったはずです。
困りましたね。でも心配無用です。ここで,リスト7の(1)のように,main関数の前に
void outx(char c);
と記述して,もう一度コンパイルし直してください。するとエラーも警告も出ず,実行ファイルが作成されます。
 リスト7●プロトタイプ宣言を実装したプログラム
リスト7●プロトタイプ宣言を実装したプログラム
この,魔法のような1行が,「プロトタイプ宣言」です。C言語のコンパイラはソースコードをファイルの先頭から順に解析していきます。outx関数についての情報がない状態でいきなり,main関数の中の「outx(c)」の行にコンパイラが出会ったら「引数にchar型の変数が指定されているけど,これでいいのか?」「outxは本当に値を返さないのか?」とコンパイラは判断に困ってしまいます。エラーが出たのはそういうわけだったのです。
でもプロトタイプ宣言をしておけば,あらかじめこの関数は引数をいくつ取って,型は何とかで,戻り値の型は何であるかという原型(プロトタイプ)をコンパイラに示しておけます。これなら,コンパイラは判断に困りません。エラーも出ないで済むというわけです。
今回は関数といっても二つだけですが,関数が数十個あって,ある関数が別の関数を呼び出し,その関数が…となるようなプログラムを作ることを想像してみてください。関数の順序などとても意識していられません。しかし,プログラムの先頭にプロトタイプ宣言をまとめて書いておけば,関数の順序を気にする必要はなくなるのです。
ちなみに,プログラムで使うすべての関数のプロトタイプ宣言をコードの先頭に書かなくてはならないかというと,そんなことはありません。randやsrand関数を使うリスト4のプログラムでは,stdlib.hを,time関数を使うためにtime.hをインクルードしました。これらの関数を使うにあたってコンパイル・エラーが起こらなかったのは,実はそれぞれの関数のプロトタイプ宣言がstdlib.hやtime.hに記述されていたからなのです。
つまり,標準ライブラリ関数と同様に,
void outx(char c);
という1行だけを記述したmyfunc.hというヘッダー・ファイルを作り,includeプリプロセッサ命令で取り込むようにすれば,たくさんのプロトタイプ宣言をプログラムの中に書く必要はなくなります*3-5。
さて,まだまだ,おぼろげかもしれませんが,プログラムの流れをどう記述するかということがわかってきたでしょうか。もし「何となく自分でもプログラムを書いていけそうだ」という気分になってもらえたら,今回の筆者の目標は達成です。次回は変数のスコープとアドレスについて解説したいと思います。ぜひ,お読みください。
CPP32でプリプロセッサの結果を出力する includeプリプロセッサ命令で,ヘッダーファイルを取り込むと説明しましたが,プリプロセッサは,構文解析をはじめとするコンパイル処理に先立ってソースコードに対してテキスト処理を行う仕組みです。
Borland C++コンパイラ(BCC32)では,プリプロセッサと構文解析を同時に行うので,プリプロセッサの結果を意識することはできませんが,付属のツール「CPP32」を使えば,プリプロセッサの結果を出力させることができます。
例えば,CPP32 ソースファイル名とコマンドプロンプトで実行すると,sample.iというファイルが作成されますので,テキスト・エディタで内容を確認してみてください。もし,stdio.hをインクルードしていれば,図Bのようにヘッダー・ファイルの内容が展開されているでしょう。-Pパラメータで,ヘッダー・ファイルなどが表示されなくなります。
 図B●ヘッダー・ファイルstdio.hがソースコード中に展開されている様子
図B●ヘッダー・ファイルstdio.hがソースコード中に展開されている様子
第4回 変数のスコープをアドレスを使って理解する
前回は,C言語がプログラムを複数の関数に分ける関数型の言語であることを説明し,制御文を使って順次/反復/分岐のロジックを作る方法を紹介しました。その前の第2回では,変数には“型”があり,浮動小数点数型では小数の計算に誤差が出ることを2進数で説明しました。そろそろ自分が作りたいプログラムを独力で作れるような気がしてきたでしょうか?
さて,今回のテーマは変数のスコープ(scope)です。実際にプログラムを書くには,変数の型だけでなく,その働きや仕組みを理解しなくてはなりません。「変数をどこに宣言すればよいのか,なんとなくわかるようになる」――それが今回の目標です。
ローカル変数とグローバル変数の違いはスコープにあり
「変数を定義する」ということは,「メモリーの一部を自分が付けた変数名(識別子)で扱えるようにする」ことです。例えばリスト1のプログラムをコンパイルすると,変数aが二つ宣言されているというコンパイル・エラーが表示されます。コンパイラの身になってみればわかりますね。「a=1」と代入するときに,どっちのaなのか特定できないのでエラーになるわけです。つまり,一つの関数の中に,同じ名前の変数を複数個定義することはできないということがわかります。
 リスト1●一つの関数内に,同じ名前の変数を複数定義することはできない
リスト1●一つの関数内に,同じ名前の変数を複数定義することはできない
リスト2はどうでしょう。main関数とoutx関数の中で,それぞれ変数aを定義しています。main関数ではaを1で初期化し,outx関数では10で初期化しています*4-1。このプログラムはコンパイル・エラーになりません。普通に実行でき,「10,1」と表示します(図1)。outx関数で「a=10」と値を代入してもmain関数側のaには影響がないので,二つの変数aは別物であると考えることができます。つまりmain関数で宣言した変数aはmain関数内で有効で,outx関数で宣言した変数aはoutx関数内で有効なわけです。
 リスト2●二つの関数で,それぞれ同じ名前の変数を定義することは可能
リスト2●二つの関数で,それぞれ同じ名前の変数を定義することは可能
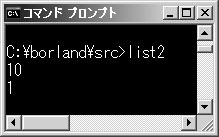 図1●リスト2を実行したところ
図1●リスト2を実行したところ
関数内で宣言した変数のことを「ローカル変数」と呼びます。また,変数が有効であるプログラム中の範囲のことを「スコープ」と呼びます。リスト2の実行結果から言えることは,「関数内で宣言されたローカル変数のスコープはその関数の中にある」ということです。
これに対し,関数の外で宣言した変数のことを「グローバル変数」と呼びます。例えばリスト3では,関数の外でグローバル変数aを宣言しています。順番に処理を追ってみると,
(1)main関数でaに1を代入
(2)outx関数でaに10を代入
(3)outx関数でaを表示
(4)main関数でaを表示
</strong>
 リスト3●関数の外で定義した変数はグローバル変数になる
リスト3●関数の外で定義した変数はグローバル変数になる
となるので,リスト2のように「10,1」と表示するような気がしますね。でも,結果は図2のように「10,10」と表示します。
 図2●リスト3を実行したところ
図2●リスト3を実行したところ
このことからグローバル変数のスコープは,関数の中だけという制約がなく,プログラム全体で有効,つまり「グローバル変数のスコープはプログラム全体である」ということが言えるわけです*4-2。
変数名が同じ場合ローカル変数が優先する
では,グローバル変数と同名のローカル変数があったらどうなるのでしょうか。リスト4を見てください。
 リスト4●グローバル変数とローカル変数で同じ変数名を使ったコード
リスト4●グローバル変数とローカル変数で同じ変数名を使ったコード
「int a=0」と,宣言とともに初期値として0を与えた変数aはグローバル変数です。main関数の中で1を代入し,printf関数で画面に表示しています。ポイントは,outx関数の中でもローカル変数aを宣言している点です。このプログラムをコンパイルしてもエラーにはなりません。同じ名前のグローバル変数とローカル変数を宣言することをコンパイラは許可しているからです。
となると疑問点はただ一つ。outx関数の中で「a=10」と10を代入しているのは,グローバル変数のaなのか,ローカル変数のaなのか,どちらなのでしょう? グローバル変数のスコープはプログラム全体で,ローカル変数のスコープは関数の中ですから,スコープがぶつかっているように思えますよね。
その答えは,実行結果を見るとすぐわかります(図3)。「10,1」の順で表示されていますね。outx関数の中で10をaに代入しても,main関数側のprintf関数の出力結果は1なので,「a=10」で10を代入されたのはローカル変数のaということになります。つまり同名の変数が宣言されてスコープが重なった場合は,ローカル変数がグローバル変数を隠ぺいするのです。同名のローカル変数が有効な範囲では,グローバル変数が雲に隠れるようなイメージだと思ってください。
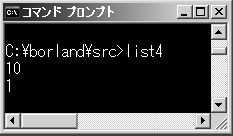 図3●リスト4を実行したところ
図3●リスト4を実行したところ
ところで,先ほどローカル変数のスコープは変数を宣言した関数の中だと説明しましたが,正確に言うと,これは間違いです。関数の始まりと終わりを示す中カッコ「{ }」にはさまれたブロックの中がローカル変数のスコープです。関数ブロックの中で宣言されたローカル変数は,閉じカッコ「}」が現れるまで有効なのです。実際に確かめてみましょう。極端な例ですが,図4のように関数ブロックの中に中カッコ({ })でブロックを作り,そのブロック内だけで有効なローカル変数を定義してみます。どうなると思いますか? 1番内側の最もローカルな変数aの値から順に出力していますので,実行すると「6,5,4」と表示されるのです。
 図4●スコープを確認するコード。色が重なっている部分はグローバル変数a,関数ブロック内で宣言されたローカル変数aが隠ぺいされる
図4●スコープを確認するコード。色が重なっている部分はグローバル変数a,関数ブロック内で宣言されたローカル変数aが隠ぺいされる
変数を生き物にたとえると,宣言された変数の型に応じて必要なメモリー領域が確保されることで始まり,値を代入したり出力に使ったあと,メモリーから解放されて一生を終えます。グローバル変数はプログラムの開始時にメモリーが確保され終了時に解放されるので,静的変数(恒久的変数)とも呼びます。それに対し,ローカル変数はブロックの始まりでメモリーに確保され,ブロックの終わりで解放されます。通常は,関数ブロック内で発生し,関数が終わるときに消えてしまいます。ですから,一時的変数(自動変数)などとも呼びます。恒久的だの一時的だの,変数にもいろいろな人生(変数生?)があるのだと思えば,変数を丁寧に扱うプログラムを書けるようになるかもしれませんね。
変数のアドレス
このあたりで,少し視点を変えてみましょう。変数を定義することは,メモリーのどこかに自分の付けた変数名で扱える場所を作ることでしたね。場所を確保すれば,値を記憶させたり,読み出したりすることができます。
どの場所に値を記憶させたかを判別するため,メモリーには「アドレス」という番号が振られています。現実世界でいうと,住所とか所番地のようなものです。メモリーのアドレスを意識させない,もしくは意識できないプログラム言語もありますが,C言語はアドレス演算子(&)を使えばアドレスを取得できるので,実際に変数がメモリーをどう確保するかを確認してみましょう。例えば図5のように,int型の変数a,bが連続してメモリー上に確保されたときのイメージを思い浮かべてください。このときのイメージをコードにしたのがリスト5です。
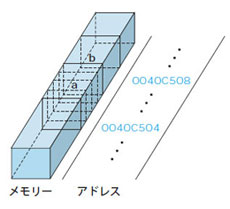 図5●int型の変数a,bが連続してメモリー上に確保されたときのイメージ
図5●int型の変数a,bが連続してメモリー上に確保されたときのイメージ
 リスト5●変数のアドレスを確認するプログラム
リスト5●変数のアドレスを確認するプログラム
グローバル変数a,bを確保し(1),main関数の中でaに16を代入して(2),bには「a×4」の結果である64を代入しています(3)。次にprintf関数でa,bの値と,変数a,bのアドレスを出力し*4-3,outx関数では,ローカル変数aに代入した16を左シフト演算子で,2ビットぶんシフトすることで4倍しています(4)(カコミ記事「シフト演算って何?」参照)。
リスト5を実行すると図6のようになります。変数のアドレスに注目してください。int型の変数は4バイトぶんのメモリー領域を使って記憶されるので,グローバル変数のaとbは並んでメモリーに場所を確保しています(図5のイメージのままですね)。ローカル変数a,bも仲良く隣り合っています。でも,グローバル変数とローカル変数のアドレスは,遠くに離れていますね。これはどういうわけでしょう。
 図6●リスト5の実行結果
図6●リスト5の実行結果
実はメモリーの内部は,弁当箱のように区切られていると考えてください。ごはんの場所,おかずの場所のように,目的に応じて図7のように仕切られているのです。
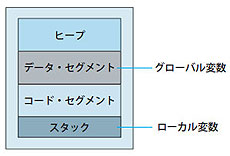 図7●メモリーがエリア分けされているイメージ
図7●メモリーがエリア分けされているイメージ
関数の引数や関数内部で宣言したローカル変数はスタックに配置されます。スタック領域は,関数が呼び出された時点で確保され,関数の処理が終わると自動的に解放されます。だから,ローカル変数の寿命は関数ブロック内に限定されるのです。
一方,グローバル変数は,データ・セグメント(静的記憶領域)に配置されます。この領域に確保された変数の寿命はプログラム終了までです。ローカル変数とグローバル変数は管理の仕方が違うエリアに確保されるのです。
シフト演算って何? シフト演算はビットをずらします。例えば,16を8ビット(1バイト)の2進数で表すと「00010000」となりますね。これを2ビット左にシフトすると「01000000」となり,10進数では64になります。逆に,右シフト演算子(>>)で2ビット右にシフトすると「00000100」となり,10進数では4になります。2進数ですから,1ビットずらすと2倍もしくは1/2倍になるわけです。つまり,10進数だと10倍あるいは1/10倍ですね。
このほかにもビット演算子には,ビット単位の論理積をとるAND演算子や,論理和をとるOR演算子などが用意されています。16進数0x01と0x02の論理積は「0x01 & 0x02」の式で求まり,結果は0です。2進数で考えると000000001と00000010のビット単位の積ですから,00000000となるのがわかります。
一方,論理和は「0x01|0x02」で求めることができ,値は00000011です。ビット単位の操作を行えば,char型やint型をTrue/False(1/0)の論理型の集合のように扱うこともできます。
スタックはPEZのディスペンサー
せっかくですから,もう少しスタックについて,突っ込んでみましょう。スタックでは後入れ先出し (LIFO :Last in First Out)方式でメモリーの管理が行われます。キャンディーを上からぎゅうぎゅう押し込み,一番上のものから1個ずつ取り出し食べていくお菓子「ペッツ(PEZ)」のディスペンサーのようなものをイメージしてください。「ペッツなんて知らない」と言われたら,他に何にたとえればいいか困ってしまうのですが,上にしか口がない筒状の容器に,何かを押し込んでいくと,最初に取り出すことができるのは最後に入れたものになりますね。そういう容器を想像してください。
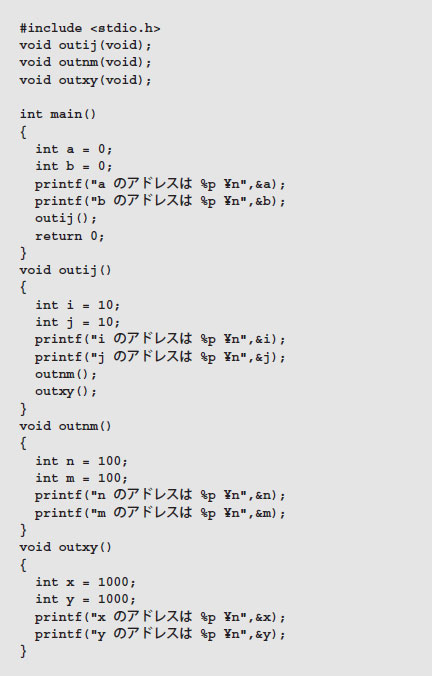 リスト6●スタックの様子を調べるプログラム
リスト6●スタックの様子を調べるプログラム
リスト6では,main関数でローカル変数a,bを宣言しています。main関数はoutij関数を呼び出し,outij関数はローカル変数i,jを宣言します。outij関数はoutnmとoutxyという二つの関数を呼び出します。実行結果は図8です。アドレスの下2桁だけを使って図解しましょう(図9)。a,b → i,j → n,mの順で各関数の開始時にローカル変数がスタックに押し込まれていきます。outnm関数が終了した時点で,n,mが取り出され,outxy関数で再びその領域が利用されます。
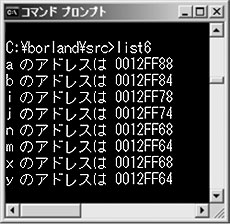 図8●リスト6を実行したところ
図8●リスト6を実行したところ
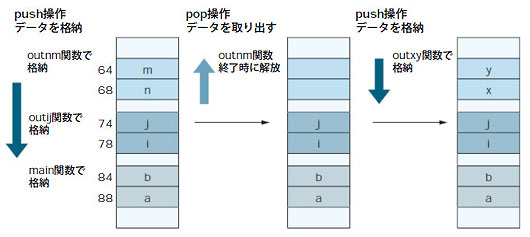 図9●リスト6におけるスタックの様子
図9●リスト6におけるスタックの様子
終了した関数の使っていたメモリー領域から,解放されるので,関数が関数を呼び出し,その関数がまた関数を呼び出すようなプログラムの構造では,このスタックの後入れ先出し方式は理にかなっています。呼び出された関数の処理が終われば呼び出し元の関数に制御が戻ってくるからです。
しかし,一般にスタックはデータ・セグメントやヒープに比べると小さい領域です。関数が何重にも関数を呼び出していくプログラムの中で,大きな変数をどんどん確保していくと,スタック・オーバーフローというエラーになることがあるので注意しなくてはいけません。大きなメモリー領域を確保したいときは,標準ライブラリ関数mallocを使って動的にメモリーを確保します。malloc関数を使った場合はヒープにメモリー領域が確保されます。ちなみに,コード・セグメントという場所はプログラム領域と呼ばれ,プログラムのコード,もろんマシン語に変換されたコードがロードされる領域です。
記憶クラス指定子staticを使ってみよう
 リスト7●staticを使ったプログラム
リスト7●staticを使ったプログラム
最後に,staticという記憶クラス指定子の効果を見てみましょう。リスト7ではグローバル変数aとローカル変数b,そしてstaticというキーワードを付けたローカル変数cを宣言しています。そして,outabc関数内のprintfで,++a,++b,++cと各変数の値をインクリメントしています(図10)*4-4。aはグローバル変数ですから,プログラム全体で値をキープできます。一方,bはローカル変数ですから,outabc関数を抜けると消滅してしまうので,インクリメントした結果は,いつも1です。しかし,staticをつけた変数cはグローバル変数と同じようにカウントアップされています。static記憶クラス指定子を付けると,静的寿命を持つローカル変数になるのです*4-5。
 図10●リスト7を実行したところ
図10●リスト7を実行したところ
でも,この説明では納得がいきませんよね。ローカル変数はスタックに確保されるから,「関数を抜ければ解放されるんでは?」と疑問を感じます。ふに落ちない場合は,アドレスを表示させて確認できるところがC言語のいいところです。
 リスト8●リスト7のoutabc( )関数のprintfの後に追加するコード
リスト8●リスト7のoutabc( )関数のprintfの後に追加するコード
リスト7のプログラムに,リスト8のような変数cの値が5のときにだけ各変数のアドレスを表示するコードを追加して,実行してみてください(図11)。ローカル変数bの横にいたはずのローカル変数cが,グローバル変数aの隣にいますね。staticという記憶クラス指定子を付けることにより,記憶場所がスタックからデータ・セグメントに変わったのです。
 図11●リスト7にリスト8のコードを追加して実行したところ
図11●リスト7にリスト8のコードを追加して実行したところ
このようにアドレス演算子を使うと,簡単に変数のアドレスを取得できるので「なぜ,そうなるの?」を自分で解決できます。
さて,次回はmalloc関数とは違う方法で,メモリーの領域をまとめて確保する方法や配列について説明したいと思います。また,お付き合いください。
第5回 配列を理解してアルゴリズムを考える
本連載も今回で5回目,いよいよ中盤に差し掛かってきました。第1回から4回までは,C言語のプログラムとアセンブラのプログラムとの対比,浮動小数点数が計算を間違う理由,構造化プログラミングの必要性,変数のスコープとメモリー・セグメントの関係,スタックの動作など基本的な知識を中心に解説してきました。「こうなるのは,こういう理由か」と,目に見えぬ仕組みを理解していただけたでしょうか。
今回からは,基本的な仕組みに加えて,プログラミングの面白さもお伝えしたいと思います。プログラミングの面白さは“考えること”にあります。どう処理すればよいかをイメージできない複雑なことを,創意工夫でスパッとコードで実現できたときの爽快感は,他の仕事では得がたいものかもしれません。例えば,大量のデータを少量のコードで扱い,処理の効率をアップさせるために知っておかなくてはならない基本的なデータ構造に「配列」があります。今回は,この「配列」にフォーカスし,配列とは何かから始め,配列を使うと何が便利なのかを知っていただきたいと思います。
同じデータが繰り返し発生するときに配列を使う
例えば,陸上競技100メートル走の結果を記録し,誰が(何コースが)1位だったかを表示するプログラムを考えてみましょう。
100メートル走のタイムは10.12などと小数点以下の値を持つので,float型で記録することにします。コースが8コースあるとすると,タイムを記録する変数も八つ必要になります。つまり,
float rtime1,rtime2,rtime3,rtime4,rtime5,rtime6,rtime7,rtime8;
とコースの数だけ別々の変数を定義し,
printf("1コースのタイムを入力してください:");
scanf("%f",&rtime1);
~
printf("8コースのタイムを入力してください:");
scanf("%f",&rtime8);
のようにscanf関数で各変数に,タイムを入力していくプログラムが思いつくでしょう*5-1。でもこれだと,変数の個数ぶん同じコードを繰り返し記述しなければならないので,冗長な感じがします。最高タイムを求めるコードも面倒なものになりそうな気がします。このように,同じ性質のデータが繰り返し発生するときに「配列」を使います。
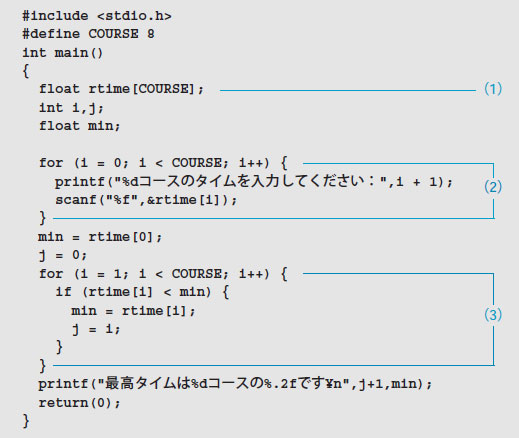
リスト1が配列を使ったプログラムです。(1)の「float rtime[COURSE]」が配列の宣言です。COURSEは#defineプリプロセッサ命令でマクロとして宣言されています。#defineは
#define マクロ名 置換する文字列
の形式でマクロを定義します。ソース・プログラム中のマクロ名はプログラムがコンパイルされる前に,プリプロセッサにより,「置換する文字列」に変換されます。ですから,これでfloat型のrtime[0]~rtime[7]までの八つの要素を持つ配列がメモリー上に確保されるのです。各コースに8人の選手がキチンと並んだように,float型の値を入れるメモリー領域が8個ぶん連続して確保されるわけです(図1)。
 リスト1●8コースぶんのタイムを記録し,一着のコースとタイムを表示するプログラム
リスト1●8コースぶんのタイムを記録し,一着のコースとタイムを表示するプログラム
 図1●1次元配列のイメージ。float rtime[8]と書くと,float型の変数を入れる箱が八つ用意される
図1●1次元配列のイメージ。float rtime[8]と書くと,float型の変数を入れる箱が八つ用意される
配列を扱う場合,マクロ定義はとても有効です。リスト1の最初のfor文のループでは,配列の添え字「i」の値を一つずつ変化させながら,scanf関数で配列の各要素に値を代入しています(2)。このforループで繰り返す回数をコントロールするためにも,「i < COURSE」とマクロCOURSEを使っていますね。このように書いておくと,コース数が変わったときに,#defineの「置換する文字列」だけを変更すればよいので便利です。
配列について一つ注意してほしいのが,C言語では配列の添え字(インデックス)は常に0から始まるという点です。他の言語では1から始まるように指定できる場合もありますが,C言語では常に0からです。ですから,printf関数の「%dコース…」の変換仕様%dにインデックス「i+1」を指定し,コース番号としています。rtime[0]が1コースのタイムを入れる配列の要素になるのです。ですから,for文の繰り返し判定もi < COURSEと8より小さかったらとシンプルに記述することができます。
最高タイムを求める処理では,まずrtime[0]を変数minに代入し,それより小さい値があったらminの値を入れ替え,インデックスの値をjに記憶しています(3)。最高タイムを表示するprintf文中の変換仕様「%.2f」は浮動小数点数を小数点以下2桁まで表示することを意味します。このプログラムを実行すると図2のようになります。最高タイムのコースとタイムを表示していますね。
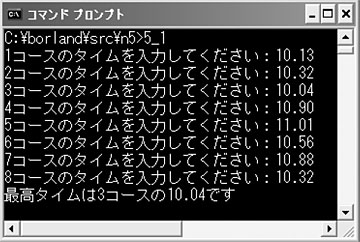 図2●リスト1を実行したところ
図2●リスト1を実行したところ
多次元配列を使うと,より多くのデータを扱える
陸上競技では,複数組の予選が行われ,勝者が決勝に残り,メダルを争います。リスト1のサンプル・プログラムは,決勝で誰が一番かを決めるようなイメージでしたが,今度は,予選の処理も考えてみましょう。
100メートル走に48名のエントリがあったので,6組に分け予選を行い,各組の最高のタイムを表示させたいとします。「それなら,1次元配列を使ったリスト1のプログラムを6回実行すれば?」――確かにそうですが,ちょっと面倒です。こんなときに便利なのが「多次元配列」です。多次元配列を使えば,6組×8コースのタイムを一つの配列として扱うことができます。
例えば,図3のような配列を宣言するには,「float rtime[6][8]」とインデックスを二つ書きます。こうすれば,8コースぶんの1次元配列が六つ格納できる2次元配列が確保できます。
 図3●多次元配列(2次元)のイメージ。float rtime[6][8]と書くと,float型の変数を入れる箱が6×8=48個用意される
図3●多次元配列(2次元)のイメージ。float rtime[6][8]と書くと,float型の変数を入れる箱が6×8=48個用意される
実際に2次元配列を実装したコードを見てみましょう(リスト2)。for文によるループを入れ子(ネスト)にして,各要素を扱っています。インデックス「i」が組に,「j」がコースに対応しています。この例では単純に各組のベストタイムを表示しているだけですが,2次元配列としてデータを表現しておけば,組(次元)ごとの処理だけではなく,配列全体を一つのデータの固まりとして扱う――例えば全体から上位3名のタイムを求めること――も可能です。
#include <stdio.h>
#define KUMI 6
#define COURSE 8
int main()
{
float rtime[KUMI][COURSE];
int i,j,k;
float min;
for (i = 0; i < KUMI; i++) {
for (j = 0; j < COURSE; j++) {
printf("%d組%dコースのタイムを入力してください:",
i + 1,j + 1);
scanf("%f",&rtime[i][j]);
}
}
for (i = 0; i < KUMI; i++) {
min = rtime[i][0];
k = 0;
for (j = 1; j < COURSE; j++) {
if (rtime[i][j] < min) {
min = rtime[i][j];
k = j;
}
}
printf("%d組の最高タイムは%dコースの%.2fです¥n",
i+1,k+1,min);
}
return(0);
}
リスト2●2次元配列を使って実装したコード
C言語では,2次元配列だけでなく,3次元,4次元と多次元の配列を扱うことができます。慣れないと扱いにくいかもしれませんが,要はインデックスが増え,for文のネストが一つ深くなるだけです。例えば,100メートル走のタイムを格納する「組×コース」の2次元配列を,100メートル走と200メートル走のタイムを格納できるように拡張しようと思ったら,
#define SYUMOKU 2
と種目の数をマクロ定義して,
float rtime[SYUMOKU][KUMI][COURSE];
で3次元配列を定義し,リスト3のようにforループの外側に,もう一つforループを追加してやればよいわけです。
for (i = 0; i < SYUMOKU; i++) {
for (j = 0; j < KUMI; j++) {
for (k = 0; k < COURSE; k++) {
printf("第%d種目%d組%dコースのタイムを入力!:",
i + 1,j + 1,k + 1);
scanf("%f",&rtime[i][j][k]);
}
}
}
リスト3●2次元配列を,100メートル走と200メートル走のタイムを格納できるように拡張したコード(一部)
素数を求めるプログラムを配列を使って作る
さて,ここまでで,変数をいくつもバラバラに宣言してプログラムを作成するより,配列を使った方が少しのコードでより大量のデータを扱えるということがわかっていただけたと思います。次に検証したいのは,配列というデータ構造を使うことで,処理そのものを効率化できるかどうかという点です。
何か解決すべき問題があって,それを解く方法のことをアルゴリズムと呼ぶのは,皆さんならご存知ですね*5-2。当たり前の話ですが,コンピュータのプログラムに限らず,何かを解決する方法は複数存在します。しかし,すべての方法がベストな選択とは限りません。複数ある解法のうち,“手順の少ない方法”が効率の良いアルゴリズムと言えます。
配列のデータを並べ替え(ソート)したり,ある値を探したり(サーチ)する処理では,いろいろなアルゴリズムが考えられてきました。クイック・ソートやバイナリ・サーチなどが有名ですね。
今回のテーマは「配列を使うと処理の効率化が図れるか」ですから,配列を使わない場合と使う場合とでプログラムを比較してみます。サンプルとして,素数を求めるプログラムを考えてみましょう。素数を求める処理にかかる回数を比較してみたいと思います。
ところで皆さんは,素数とは何かをきちっと言えますか? そう,1とその数自身以外では割り切れない整数です。間違えやすいのですが,1は特別な数で,素数ではありません。2以上の数は,素数と合成数*5-3で構成されています。例えば,20までの素数は図4のようになります。
 図4●20までの素数と合成数
図4●20までの素数と合成数
リスト4のコードが,配列を使わずに素数を求めるサンプル・プログラムです。2からMAX(1000)までの範囲にある素数を求めています。ある数が素数であるか否かを調べるには,自身と同じ数でしか割り切れないことを調べればよいわけですから,変数「i」の値を変数「j」で割った余りが0のとき*5-4,iとjがイコールであれば,素数であると判断*5-5できます。プログラムでは,2から1000まで増加していくiの値をjで割っています。jは2から始まり,iまで増加していきます。「i==j」が成り立つ前に割り切れてしまった場合は,合成数だと判断できます。
#include <stdio.h>
#define MAX 1000
int main()
{
int i, j;
int counter1 = 0,counter2 = 0,counter3=0;
for(i=2;i<=MAX;i++) {
for(j=2;j<i;j++) {
counter1++;
if(i % j == 0) {
break;
}
}
if (i==j) {
printf("%d¥n",i);
counter3++;
} else {
counter2++;
}
}
printf("計算した回数%d¥n",counter1);
printf("合成数の数%d¥n",counter2);
printf("素数の数%d¥n",counter3);
return 0;
}
リスト4●配列を使わずに,素数を求めるプログラム
counter1が剰余を求める計算をした回数を記憶する変数,counter2が合成数の数,counter3が素数の数です。実行結果は図5のようになります。素数の数が168で,それ以外の831個が合成数です。
 図5●リスト4を実行したところ
図5●リスト4を実行したところ
注目してほしいのは,計算した回数7万8022という数字です。iとjの剰余が0と等しいかどうかという評価処理を,7万8022回行っているわけです。かなりの数ですね。はたして,2から1000までの素数を求めるのに7万8022回も処理が必要になるのは仕方のないことなのでしょうか? もちろん,7万8022回といっても,コンピュータは一瞬で計算してしまいますから,特に不満は感じないかもしれません。しかし,大規模なプログラムになればなるほど,プログラムのあちこちで繰り返し計算を行うことになります。一つの計算に要する時間はわずかでも,それがいくつも積み重なると,プログラム全体の処理時間は長くなります。プログラマなら,一つひとつの処理に無駄がないかをキチンとチェックすべきなのは言うまでもありません。
エラトステネスのふるいを使って素数を求める
では,もっと少ない手順で素数を求める方法はないのでしょうか? そこで,アルゴリズムの登場です。
古くから知られている素数を調べるアルゴリズムに「エラトステネスのふるい」があります。合成数をふるい落としていく方法です。まず,1から10までの素数をエラトステネスのふるいで求める方法を考えてみましょう。まず,1は特別な数ですから,ふるい落とします。次に,2は素数ですからそのままにして,2の倍数をふるい落としていきます。
4,6,8,10
がふるい落とされました。次に,3の倍数,4の倍数と落としていきます。
6,9
8
5の倍数「10」を落とした時点で素数が確定します。残ったのは,2,3,5,7です。このふるいを,配列を使って表現してみましょう。1000の要素を持つ配列を用意して,ふるいとして使います(リスト5)。
 リスト5●アルゴリズム「エラトステネスのふるい」を使って素数を求めるプログラム
リスト5●アルゴリズム「エラトステネスのふるい」を使って素数を求めるプログラム
(1)でfurui配列を初期化しています。(2)は「1は特別な数で素数ではない」を意味するコードです。C言語の配列はインデックス0から始まるのでfurui[0]は数字の1に対応しています。1000はfurui[999]です。furui[i]に1を代入することが,「ふるい落とすこと」を意味します。(3)のループの中で, furui[i * j -1]に1を代入していきます。iは2から始まり,MAX÷2までインクリメント(増加)します。jも2から始まり,「i*j」がMAXになるまで,インクリメントします。つまり,
2*2-1,2*3-1,2*4-1,2*5-1,2*6-1,…
3*2-1,3*3-1,3*4-1,3*5-1,3*6-1,…
4*2-1,4*3-1,4*4-1,4*5-1,4*6-1,…
…
と倍数がふるい落とされていくわけです。(4)のif文では,すでに1が代入されているかをチェックし,1が入っていないときに1を代入しています。counter2がふるい落とした数になります。素数かどうかを評価した回数はif文で「furui[i*j-1]==0」とたずねた回数とイコールですから,if文を抜けたあとでcounter1をインクリメントしています。(5)でふるい落とされずに残った数を配列のインデックス「i + 1」で表示しています。
リスト5の実行結果は図6の通りです。素数の数は168で,リスト3の結果と同じですね。違いは「ふるいにかけた回数」と表示している評価を行った回数です。なんと5070回。7万8022回のリスト3に比べ激減しています。この結果を見ると,配列を使うことで処理の効率化は可能だと言えます。
 図6●リスト5を実行したところ
図6●リスト5を実行したところ
とはいえ,効率化できたからといって満足するだけではいけません。一般的に処理速度を上げようとすると,メモリーの使用量が増えるというトレードオフが発生します。今回は,リスト4の処理を,リスト5のように配列を使った処理に変更することで,int型の要素1000の配列ぶんのメモリー(4×1000バイト)が必要になりました。ここで,「この程度の処理速度なら,適切なメモリー使用量かな?」と,処理速度とメモリー使用量のバランスを考えるバランス感覚を持つことがプログラマには必要だと筆者は思います。
アルゴリズムと可読性のバランスを考えるようにしよう
「それでは,お後がよろしいようで」と終わりにしたいところですが,もう一度リスト5を見直してみましょう。
このプログラムでは,furui[i*j-1]が0のときだけ,つまり,すでに1(素数でない)というマークが付いてないときだけ1を代入していますが,そこに1が入っているということがあらかじめわかっている数を飛ばすことができれば,もっと無駄な処理を省けます。
(3)のループで,最初に2以外の2の倍数にマークを付けるのですから,2以外の偶数はすべて素数ではないと1が代入されているはずです。ならば,4以上の2で割り切れる数は,スキップしてもいいんじゃないかというコードがリスト6の(1)です。iが3より大きくて,2で割った余りが0のときは,continue文でループの先頭に飛ばし,以降の処理が実行されないようにしています。このように変更すると,ふるいにかけた回数が2879回に減りました(図7)。
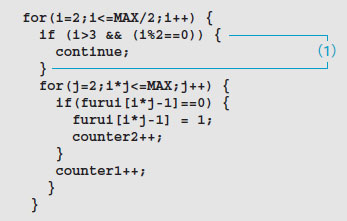 リスト6●リスト5の(3)のループを効率化したコード(一部)
リスト6●リスト5の(3)のループを効率化したコード(一部)
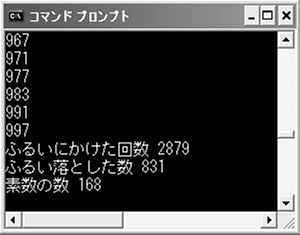 図7●リスト5をリスト6のコードで修正して実行したところ
図7●リスト5をリスト6のコードで修正して実行したところ
この変更による効率化は,使用するメモリー資源を増やすものではありません。単に無駄な処理はしないという工夫です。何のトレードオフも発生していないように見えますね。
しかし,実はそれでもトレードオフは発生しているのです。それは,自分以外の人間にプログラムを見せたときのわかりやすさです。リスト5のコードは,エラストテネスのふるいを知っていれば,何をしているのか一目瞭然です。しかしリスト6の修正の意味は,パッと見ただけでは,よくわかりません。
/* 2の倍数には最初に1を代入済み */
などとコメントを入れておけば,処理内容を説明する必要はないでしょう。しかし,コードを追加していけばいくほど,プログラムを読むことが難しくなってくることは避けられません。このことを「プログラムの可読性が下がる」と言います。
プログラマは,処理効率化のためのプログラムの改変が,わかりやすさとのトレードオフになるということを意識しなければいけません。「ここを直したら,もう少し速くなるけど,わかりにくくなりそうだから,やめておくか」というバランス感覚もプログラマには必要だと筆者は考えます。
次回は文字列を扱う方法を,ポインタの解説を交えてお送りしたいと思います。
第6回 ポインタを理解して文字列を扱う
本連載も今回で折り返し地点の第6回となりました。前回は,エラトステネスのふるいを使って素数を求めるプログラムを作成し,ロジックを考えてプログラムを作ることの面白さをお伝えしました。今回は文字列の扱い方とポインタの基礎を解説して,暗号化プログラムを作成してみます。
インターネットの普及とともに暗号化技術の研究も盛んになっていますね。とはいってもここでは最近用いられるような難解な暗号ではなく,古代ローマのジュリアス・シーザーが使ったといわれるシーザー暗号をプログラミングしてみましょう。*6-1
なぜ文字列とポインタの知識が必要なのか
暗号化の話に入る前に,いま一度,C言語とはどんなコンピュータ言語なのかを振り返っておきたいと思います。1970年代に米AT&T社のベル研究所でD. M. Ritchie氏とB. W. Kernighan氏によって開発されたC言語は,C#やJavaを始めとする多くの言語に影響を与えただけでなく,オブジェクト指向化されたC++言語とともに,現在でも広く使われています。しかし普及したからといって,C言語を甘く見てはいけません。Cをプログラムするとき,プログラマは常にCの危険性を肝に銘じておく必要があります。
一つ目は「ポインタ演算などの機能を持ち,アセンブラのようなハードウエアに密着した操作ができる」ことです。これはOSを書くためには必須のもので,もともとC言語はUNIXを書くために作られたのですから,当然といえば当然ですね。
もう一つは「文字列はNULL文字でターミネートする配列であり,配列操作の実体はポインタ演算である。標準ライブラリに用意されている文字列を操作する関数はバッファ・オーバーフロー*6-2を考慮していない」という点です。
文字列操作やポインタは,便利な半面,操作を誤ると思わぬバグを引き起こします。実際,ポインタ演算の機能は,バグの原因やコンピュータを暴走させる危険性があるという理由で,Javaなどでは省かれています。
C言語にはそういった危険な要素があるんだぞということを理解しつつ,バグを作らないためにも,文字列とポインタの基礎をしっかり身に付ける必要があるのです。
文字列は文字 (char型)の配列で扱う
Javaなどの言語では,複数の文字を並べた“文字列”を扱うためにString型という型が用意されています。しかし,C言語には文字列を扱う型がありません。そのためC言語では,文字(char型)の“配列”として文字列を扱います。
例えば,「Jonny」という文字列を扱うときは,リスト1のように配列に代入する必要があります。(1)で1バイト文字が0から9の10文字ぶん格納できる配列を宣言し,(2)以降で一文字ずつ代入しています。(3)で代入している「\0」はNULL*6-3文字を表すエスケープ文字です。C言語の場合,文字列はNULLでターミネート(終了)します。難しく聞こえるかもしれませんが,NULLを文字列の終わりとして判断する記号に使っているわけです。土の中に,Jonnyという名前を一文字ずつ記入したカプセルを埋めたとイメージしてください(図1)。掘り出していくと,J,o,n…と順番に文字が出てきます。yまで掘っても,これで終わりだよというマークがなければ,「まだ,何かあるんじゃないか」と掘るのを止めることができません。この「これで終わりだよマーク」がC言語ではNULLなのです。ですから,文字列を格納する場合は文字数プラス(NULLのための)1バイトが必要なのです(図2)。
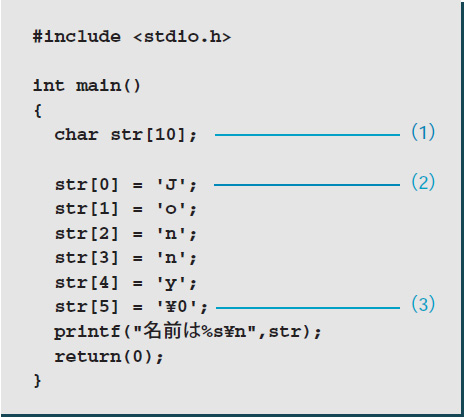 リスト1●Jonnyという文字列を配列に格納するプログラム
リスト1●Jonnyという文字列を配列に格納するプログラム
 図1●埋まっている文字列の最後にあるのが「¥0」
図1●埋まっている文字列の最後にあるのが「¥0」
 図2●文字列を格納する場合は文字数プラス1バイトが必要
図2●文字列を格納する場合は文字数プラス1バイトが必要
文字(char)型で,「a」を記憶するには1バイトしか必要ありません。しかし,文字列として(char型の配列として),「a」1文字を記憶するには,2バイト必要になるわけですね*6-4。
しかし,文字列を扱うのにいちいちリスト1のように書いていたら大変です。文字列の配列の初期化は,リスト2の(1)のようにまとめて書くこともできますし,(2)のようにダブルクォートでくくって記述することもできます。この場合は末尾に自動的にNULLが付加されます。どう考えても(2)の方が簡単ですよね…。ただし,このとき文字列はダブルクォートでくくり,文字はシングルクォートでくくる点に注意してください。なお,コードの途中で
char str2[10]="Lucy";
~
str2[10]="Linda";
のようにして文字列を代入することはできません。コンパイル・エラーになります。文字列配列に他の配列を代入することはできないからです。
 リスト2●文字列の配列の初期化は,ダブルクォートでくくって記述できる
リスト2●文字列の配列の初期化は,ダブルクォートでくくって記述できる
配列名は配列の先頭アドレスを表す
リスト3は,キーボードからの入力を文字列配列に格納して表示するプログラムです(図3)。ここで思い出してほしいことは,scanf関数は2番目の引数に変数の“アドレス”を要求する関数だということです。
#include <stdio.h>
int main()
{
char str[256];
printf("名前を入力してください:");
scanf("%s",str);
printf("こんにちは,%s\n",str);
return(0);
}
リスト3●入力された文字列を表示するプログラム
 図3●リスト3を実行したところ
図3●リスト3を実行したところ
つまり,図3のように「Jinny」と入力してJinnyと無事表示されているということは,“配列名strが配列の先頭アドレスを表している”ということにほかなりません。ぜひ,ここで「配列名は配列の先頭アドレスを表す」と覚えておいてください。
ところで先ほど,初期化以外に,ダブルクォートでくくった文字列を配列に代入することができないと説明しましたが,ある文字列配列の内容を変更したい場合に1文字ずつ代入するのは手間がかかります。そこで,C言語には標準ライブラリ関数として文字列を操作する関数がいくつか用意されています。
リスト4を見てください。(2)のstrcpyが,文字列配列に他の配列をコピーする関数です。lastname配列をfullname配列にコピーしています。(3)のstrcatは文字列の連結を行う関数です。文字列を扱う標準ライブラリ関数を使うには,(1)のようにヘッダー・ファイルstring.hをインクルードする必要があります。
 リスト4●文字列処理に標準ライブラリ関数を使ったプログラム
リスト4●文字列処理に標準ライブラリ関数を使ったプログラム
実はこのプログラム,strcatを使って第1引数fullnameにfirstnameの内容を連結するときにバッファ・オーバーフローが発生します。fullnameのサイズがSuzukiとIchiroを連結して格納するには小さすぎるからです(図4)。もし,あふれた部分を他の変数や,他のプログラムが使っていたら,予期せぬ現象が起きる可能性があります。
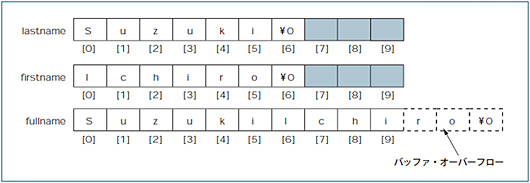 図4●リスト4のプログラムではバッファ・オーバーフローが発生する
図4●リスト4のプログラムではバッファ・オーバーフローが発生する
コンパイラはあふれをチェックしてくれません。したがってCのプログラムを作るときは,プログラマは十分な大きさの配列を確保するように気を付けなくてはいけないのです*6-5。この場合,文字列配列のNULLを除く文字数を返すstrlen関数を使って,文字数をあらかじめ調べてから連結を行う方法も有効でしょう*6-6。
文字をずらしてシーザー暗号をプログラムしてみよう
さて,文字列の扱い方の解説が済んだところで,いよいよ冒頭で述べた「シーザー暗号プログラム」を考えてみましょう。
ローマのスエトニウスが著した「カエサル伝」には「カエサル(シーザー)の書いた暗号文を読み取るには,各文字をアルファベットの順で三つ前の文字に置き換えなければならなかった」という記述が残っているそうです*6-7。ここでは,必ず3文字ずらすだけではなく,何文字ずらすかを指定できるようにしてみましょう。また,複雑になりすぎないように暗号化する文字は英大文字だけを対象にします。
リスト5が,シーザー暗号プログラム,いわゆる換字式暗号化プログラムのサンプルです。冒頭で「#define LEN 255」となっていますが,#defineで配列の要素数をマクロ定義する方法はC言語の定石ですね。str配列は,暗号化前の元の文を入れる配列です。暗号化した文字列はcipher配列に格納します。ikeyは何文字ずらすかという“鍵”です。while文によるループの中で文字のずらし(シフト)を行っています。繰り返し条件が「str[i]!=’\0’」ですから,元の文のNULLに出会うまで繰り返し暗号化を行います。ループを抜けたら,「cipher[i]=’\0’」で暗号文にNULLを付加していますが,これを忘れると,どこまで文字が入っているのかわからなくなるので注意してください。
 リスト5●換字式暗号化プログラムのサンプル
リスト5●換字式暗号化プログラムのサンプル
このプログラムの中でわかりにくいのは(1)の部分でしょう。「str[i]-‘A’」は英大文字を表1のように,0から始まる連番に置き換えています。そして鍵を足して「ずらし」,26で割ったあまりを求めています。Zを1文字ずらすとAになるようにしているわけです。(2)でnにAの文字コードを足して,暗号化文字を求めています。実行結果を見ると,「ZOO」を2文字ずらしたので「BQQ」になっていますね(図5)。
 表1●リスト5の暗号化処理で,英大文字は0から始まる連番に置き換わる
表1●リスト5の暗号化処理で,英大文字は0から始まる連番に置き換わる
 図5●リスト5を実行したところ
図5●リスト5を実行したところ
ポインタを使って文字列処理を実装する
アップテンポで進めていきましょう。暗号プログラムをバージョンアップするために,ポインタについてちょっと詳しく解説します。
プログラミングの勉強をしている多くの人がぶち当たる壁が二つあります。それは,BASICや他のプログラム言語の経験者がC言語のポインタに初めて出会ったときと,非オブジェクト指向言語の経験者がオブジェクト指向言語でプログラムを作らなければいけなくなったときです。筆者もオブジェクト指向言語の様々な機能を見ていると,なぜこんな機能が必要なのかと感じることがありますが,言語の開発者はあった方が便利だと考えたに違いありません。ポインタもしかりです。ポインタはC言語最大の難関などと言われていますが,「ポインタが使えると便利になる」程度に考えておけば,それほど難しい話ではありません。
ポインタとは,変数の「値」を直接操作するのではなく,変数の「アドレス」を介して間接的に操作できるようにするための仕組みです。リスト6とその実行結果(図6)を見てください。リスト6では変数を二つ宣言していますね。「a」はint型の普通の変数です。「a=31」と整数値を代入していますので,「aの値は31」と表示します。アドレス演算子&を使って変数aのアドレスを取得すると0012FF88と表示されます。皆さんおわかりのように,0012FF88は16進数です。16進数は1桁で0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,Fまでの16通りの値を表すことができます。16進数1桁で2進数の4桁,0000から1111までを表現することができるので,アドレスは「4ビット× 8桁=32ビット」で表現されていることがわかります*6-8。
#include <stdio.h>
int main()
{
int a;
int *p;
a = 31;
p = &a;
printf("aの値は%d \n",a);
printf("aのアドレスは%p \n",&a);
printf("ポインタpの値は%p \n",p);
printf("ポインタpのアドレスは%p \n",&p);
printf("ポインタpの指す値は%d \n",*p);
return 0;
}
リスト6●ポインタを使ったプログラムのサンプル
 図6●リスト6を実行したところ
図6●リスト6を実行したところ
「int*p」がポインタの宣言です。この場合,ポインタ変数pのことを「int型へのポインタp」と呼びます。ポインタは他の変数のアドレスを記憶する変数なので,「p=&a」で変数aのアドレスを代入しています。ポインタを使う前には,必ず他の変数と関連付けなければならないことを覚えておいてください。他の変数のアドレスを代入するまでは,ポインタにはどんな値が入っているかわからないからです。
図6を見ると,ポインタpの「値」は0012FF88となっています。またポインタの「アドレス」は0012FF84となっています。ポインタといっても変数の一つですから,他の変数と同様にメモリー上に存在します。そして,間接参照演算子(*)を付けることで,ポインタが示すアドレスの内容を間接的に取得できるのです(図7)。
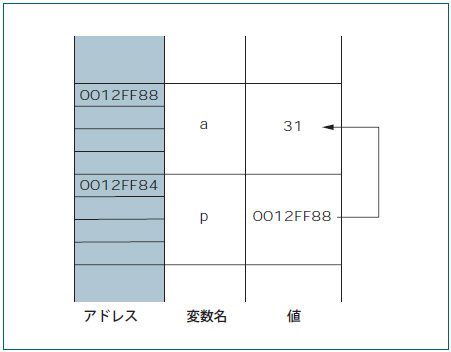 図7●リスト6におけるポインタの値とアドレスのイメージ
図7●リスト6におけるポインタの値とアドレスのイメージ
メモリーには1バイト単位でアドレスが振られており,そのアドレスをポインタ変数に記憶させることで,間接的に変数の値にアクセスできるわけです。変数aとポインタ変数pが4バイト離れているのは,本連載で使用しているBorland C++ Compiler 5.5が,int型を4バイトの領域を使って記憶するからです。またポインタ変数も,32ビットのアドレスを記憶するために,4バイトのメモリー領域を使います。しかし,アドレスを記憶するために,「int *p」とint型で4バイトのメモリー領域を確保するわけではないのです。では,ポインタを宣言するときの「型」とは何を意味しているのでしょうか?文字列配列をポインタで操作するサンプルを見ていきましょう。
ポインタに型が必要な理由
リスト7は,英単語の入力を受け付け,一文字ずつ添え字を増加させて(インクリメント)出力する方法(1)と,ポインタをインクリメントして出力する方法(2)を比較したプログラムです。当然,同じ単語が2度出力されます。ポインタstr_ptrはchar型の配列を指すポインタなので,char型で宣言しています。
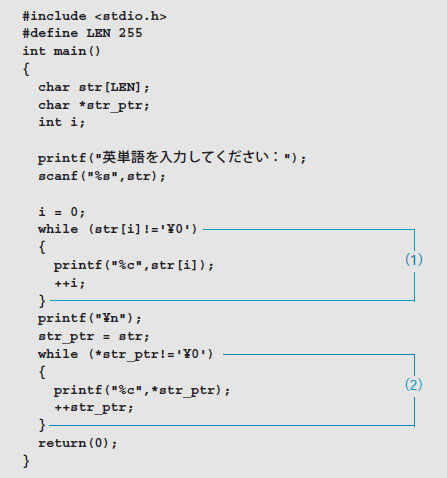 リスト7●文字列配列をポインタで操作するプログラム
リスト7●文字列配列をポインタで操作するプログラム
もう一つ,int型の配列をポインタで操作するプログラムを見てみましょう(リスト8)。int型のten配列を指すポインタ変数ten_ptrを「intten_ptr」と宣言しています。int型の配列はNINZU個の要素を持つ配列なので,forループで数字を一つずつ出力しています。ここでは,「(ten_ptr+i)」と,直接ポインタの値をインクリメントするのではなくiの値を0~4へと変化させることで,アドレスを変化させ,順に値を取り出しています。
#include <stdio.h>
#define NINZU 5
int main()
{
int ten[NINZU] = {92,70,94,85,100};
int *ten_ptr;
int i;
ten_ptr = ten;
for (i = 0; i < NINZU; i++) {
printf("%d \n",*(ten_ptr+i));
}
return 0;
}
リスト8●int型の配列をポインタで操作するプログラム
リスト7とリスト8を比べると,ポインタの値を直接変化させるか間接的に変化させるかという違いはありますが,ポインタを一つずつインクリメントさせていることに違いはありません。片方はchar型(1バイトで記憶)の配列で,もう一方はint型(4バイト)の配列なのに,1を足すとどちらも次の要素を指すのは,ポインタに「型」を宣言しているからです。char型ならchar型のサイズぶん,int型ならin型のサイズぶん,アドレスを変化させてくれるのです。
このようなことから,“配列操作はポインタ演算で実現されている”ということが実感できるのではないでしょうか。
シーザー暗号プログラムを改良する
最後にリスト5を発展させて,もう少し解きにくい暗号プログラムを作ってみましょう。リスト5の暗号プログラムでは,英文字の出現頻度などから,暗号鍵を推測することは名探偵コナン君*6-9でなくても容易ですからね。
一つの鍵で文字をずらすだけでは規則性に気づかれやすいので,複数の鍵,具体的には三つの数字を使うようにしてみます(リスト9)。図8のように,暗号化する文字列を入力したあとに鍵を三つ入力してもらいます。
 図8●リスト9を実行したところ
図8●リスト9を実行したところ
 リスト9●リスト5の暗号プログラムを改良したもの
リスト9●リスト5の暗号プログラムを改良したもの
リスト9のプログラムで注目してほしいのは,暗号化を行うcs_cipher関数に実引数として配列名を与えているところと(1),それらをポインタとして受け取り処理しているcs_cipher関数(2)です。ポインタを使うと,複数の配列を簡潔なコードで扱えることがおわかりいただけるでしょうか。これもひとえに,「++str」などとポインタ演算ができるからです。(3)は1文字目には1番目の鍵を,2文字目には2番目の鍵,3文字目には3番目の鍵,4文字目にはまた1番目の鍵を…,とikey配列の要素を選択するための処理です。よくわからない方は,文字列とポインタの関係をもう一度復習してプログラムをながめてください*6-10。
いかがでしたか?今回の内容は,はじめてC言語に触れた方には,ちょっと難しく感じられたかもしれませんね。次回以降もプログラミングの面白さとともに「へー,なるほどな」と新しい発見のある記事を書いていきたいと思います。ぜひ,またお会いしましょう。
第7回 再帰処理と参照渡し(モドキ)のメリット・デメリット
前回は文字列とポインタの関係について説明しました。C言語では文字列は「文字の配列」であり,ポインタを使うことで文字列を少ないコードでスッキリと扱えることを示しました。ポインタは他の変数のありか(アドレス)を値として持つ変数であり,ポインタの値を一つずつ増やすことで,文字列を1文字ずつ操作していくことができるからでしたね。
今回解説するのは,関数とポインタの関係です。連載の3回目でC言語の関数の引数は「値渡し」であることを説明しました。ここで,もう一度確認しておきましょう。
#include <stdio.h>
void func1(int a) ;
int main()
{
int a = 10;
func1(a);
printf("aの値は%d (main)\n",a);
return 0;
}
void func1(int a) {
a /= 2;
printf("aの値は%d (func1)\n",a);
}
リスト1●C言語の関数の引数は「値渡し」
リスト1は,main関数で変数aを宣言すると同時に10で初期化し,func1関数に引数として渡すプログラムです。実行すると図1のようになります。func1関数ではaを2で割って表示させていますが,main関数に戻って再度aの値を表示させると10のままですね。これが値渡しの効果です。main関数で「int a=10;」としたときに,aという変数がメモリー上に確保されるのと同様に,変数aの値を引数として渡したときに,main関数のaとは別にfunc1関数用の変数aがメモリーの別領域に確保されるのです。ですから,func1側でaの値を更新してもmain側の変数aには何の影響もありません。*7-1
 図1●リスト1を実行したところ
図1●リスト1を実行したところ
なぜCは値渡しなのか
一般的にプログラミング言語の関数への引数の渡し方には,値渡し(call by valueあるいはpass by value)と参照渡し(call by referenceあるいはpass by reference)の2種類があります。値渡しとは前述のように値そのものを渡すことをいいます。値渡しには,関数内のローカル変数の値を他の関数から変更されることがないので,関数の独立性が高まるというメリットがあります。
これに対し,参照渡しは変数の参照情報を渡します。参照渡しの場合は,仮にリスト1で考えると,func1側に変数aのコピーが作成されるのではなく,main関数側でメモリーに確保した変数aをfunc1からも参照することになります。参照渡しだと,メモリー上に1個だけaという変数名の領域が確保され,main関数側からもfunc1関数側からも同一の変数を更新できるようになるのです。リスト1でいうと,「a/=2」とした後のaをmain関数で表示させると5となります。
厳密な言い方をすると,C言語では値渡ししかできません。しかし,値渡しだけでは不都合な場合もあります。例えば関数は一つの値しか返しませんので,10と3といった二つの整数を引数とすることはできても,10÷3の「商」と「余り」のような二つの値を返すことはできません。そのような場合にC言語では,ポインタを使って「参照渡しのようなこと」を実装できます。変数のアドレスをポインタで受け取り,間接参照演算子を使って他の関数内で宣言されている変数の値を変更できるのです。具体的な例は後ほど紹介することにして,なぜC言語が値渡しをデフォルトにしているのか,参照渡しのデメリットも考えてみましょう。
参照渡しだと,Aという関数の中で宣言した変数の値を別の関数Bで変更できてしまいます。となると,値渡しとは逆に関数間の依存性が高くなってしまいます。また,不用意に参照渡しを行うことで,各関数の中で本当に更新される変数はどれかわかりにくくなってしまいます。値渡しの方がシンプルでプログラムの見通しがいいですよね。
それからもう一つ。プログラマならぜひ覚えておきたい「再帰呼び出し」というテクニックは,値渡しでないと実現できません。そこで以降は,少し回り道になりますが再帰呼び出しから解説し,その後でポインタによる参照渡しへとお話を進めていきましょう。
再帰呼び出しとは
皆さんは「階乗の計算」を覚えていますか? 5の階乗なら「5!」と表記し,
5! = 1 × 2 × 3 × 4 × 5
と計算します。つまり答えは120です。これをこのまま関数化すると,リスト2のfact関数(1)のようになります。iの値に1を加算し,入力された整数以下の間,掛け算を続けることで階乗を求めています。このプログラムを例に,再帰呼び出しについて考えていきましょう。
 リスト2●階乗を計算するプログラム
リスト2●階乗を計算するプログラム
再帰呼び出し (recursive call)とは,関数の中から自分自身を呼び出すプログラミングのテクニックです。わかりにくいですね。頭の中でロシア民謡を演奏しながら*7-2,図2のマトリョーシカ*7-3を見てください。マトリョーシカは女の子の形をした人形で,入れ子式になっていて,たいていの場合胴体が上下に分かれ,中から一回り小さな人形が次々と出てきます。このイメージで階乗の計算式を考えてみると,
n! = n × (n-1)!
と定義できることがわかるでしょうか。nの値はマトリョーシカのようにどんどん小さくなっていくわけです。
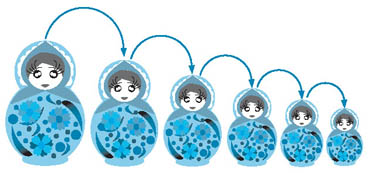 図2●再帰呼び出しは,ロシアの民芸品マトリョーシカをイメージしよう
図2●再帰呼び出しは,ロシアの民芸品マトリョーシカをイメージしよう
リスト3のfact関数(1)が,再帰呼び出しによる階乗計算の例です。fact関数の中で「fact(n - 1)」と自分と同じ関数を呼び出していますね。リスト2のfact関数と比べると,forループがなくなっていることもわかります。このように,再帰呼び出しを利用すれば,複雑な処理を単純なコードとして実現できるわけです。
 リスト3●再帰呼び出しを使ってリスト2を書き換えた
リスト3●再帰呼び出しを使ってリスト2を書き換えた
再帰呼び出しを使う二つの条件
再帰呼び出しを行うには,以下の二つの条件を満たす必要があります。
- (1)再帰呼び出しには,必ず終点(再帰を止める条件)がなければならない
例えばリスト3のfact関数では,「n==0」が終了条件です。終了条件がないとプログラムが暴走したり,異常終了します。
- (2)問題を徐々に単純にしていかなければならない
これも当然です。問題が複雑になっていくと,終わりませんからね。「fact(n - 1)」はfact(n)よりシンプルです。
int fact(int n)
{
printf("%p \n",&n);
if (n==0)
return(1);
return (n * fact(n - 1));
}
リスト4●リスト3のfact関数に,nのアドレスを表示するコードを追加した
ここでぜひ忘れないでほしいのは,再帰呼び出しを行うと,関数を呼び出すたびに引数やローカル変数がメモリーを確保するという点です。リスト3だと,fact関数が呼び出されるたびに,新しい変数nがメモリー上に作られるのです。nは決して一つではありません。ですから「n*fact(n-1)」と計算できるのです。リスト3のfact関数にnのアドレスを表示するコード(リスト4)を追加してみれば理解できるでしょう。5の階乗を計算したとき,nが0のときも含めて6個のアドレスが表示されました(図3)。引数のコピーが作成される値渡しでないと,再帰呼び出しが実現できないことがわかります。
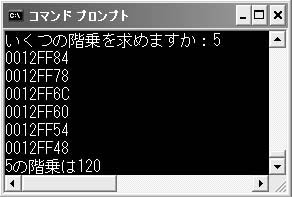 図3●リスト3のfact関数をリスト4に書き換えて実行したところ
図3●リスト3のfact関数をリスト4に書き換えて実行したところ
もう一つ知ってほしいのは,C言語が変数を記憶するヒープ,データ・セグメント,スタックの三つの領域のうち,引数やローカル変数は比較的狭いエリアであるスタックに記憶されるということです。つまり,階乗計算のような単純なサンプルでも,大きな値の階乗を求めるとスタック用のメモリーを大量に消費するのです。
「ハノイの塔」問題を再帰呼び出しで解く
インドのガンジス川近くベナレスに,世界の中心を表すバラモン教の大寺院があり,3本の大理石の柱が立っているという。神はその1本に64枚の金の円盤をはめられた。バラモンの僧侶たちはそれを別の柱に移し替えているが,以下の三つを守らねばならない。
(1) 一回に一枚の円盤しか動かしてはいけない
(2) 小さい円盤の上に大きい円盤を載せてはいけない
(3) 3本の柱以外の場所に円盤を置いてはいけない
移し替えが完了したとき,世界は崩壊する…。
皆さんも一度は聞いたことがありませんか? 有名なハノイの塔の問題です。「世界は崩壊する」なんて物騒なことを言ってますがご安心ください。三つのルールを守る限り,1秒間に1枚移動させたとしても,約5850億年かかるそうです。
このハノイの塔というパズルは,フランスの数学者リュカ(Edouard Lucas)が1883年に考えたもので,古代インドの神話をもとにしたとも言われています。数学者は文学者よりもおもしろい絵空事を思いつくものですね。
簡単にするために,3枚の円盤で考えてみましょう。3枚だと,ちょうど7回の操作でA軸からC軸に円盤を移動させることができます(図4)。この場合,B軸は作業用の場所として使用します。では,枚数に関係なく適用できるアルゴリズムはどうなるでしょうか。ちょっと難しそうですね。ところが,ここで再帰呼び出しを使うと,実に簡単にプログラミングできるのです。
 図4●円盤の枚数を3枚にしたときのハノイの塔の解法手順
図4●円盤の枚数を3枚にしたときのハノイの塔の解法手順
リスト5のhanoi関数がその実装例です。順にコードを見ていきましょう。まず,3本の柱にA,B,Cという名前を付けるために,jikuという文字型の配列を作成しています(1)。hanoi関数の引数x,yとローカル変数zが,jiku配列の添字にあたります*7-4。
 リスト5●再帰呼び出しを使ったハノイの塔の解法プログラム
リスト5●再帰呼び出しを使ったハノイの塔の解法プログラム
scanf関数で円盤の枚数を受け取り,「hanoi(n,0,2)」で引数として渡しています(2)。2番目の引数が移動元の軸の番号「0」で,3番目が移動先の軸を示します。nが円盤の枚数ですから,3が入力された場合,円盤は一番小さいものから順に「1(=n-2)」,「2(=n-1)」,「3(=n)」となります。(3)の「int z = 3 - x - y」は作業用の軸を求めます。A軸の添え字が0,B軸が1,C軸が2なので,「hanoi(n,0,2)」と引数が与えられた場合の作業軸は1,つまりBです。x,y,zの値の変化に注目しながら,コードを追っていってください。(4)は1からn-1までの円盤を作業用の軸に移す処理,(5)が円盤nを移動先の軸に移す処理,(6)が1からn-1の円盤を作業用の軸から移動先の軸に移す処理になります。
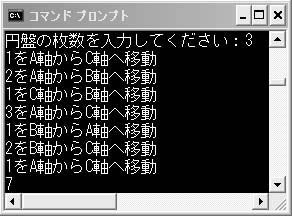 図5●リスト5を実行したところ
図5●リスト5を実行したところ
実行してみると,図4の手順通りに移動していることがわかるでしょうか(図5)。手順を追っていくと,図6のようにn,x,y,zの値が変化して,円盤が移動されていくことが理解できると思います*7-5。
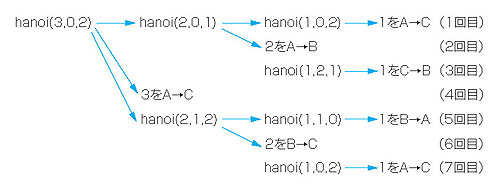 図6●hanoi関数が実行されていく様子
図6●hanoi関数が実行されていく様子
再帰呼び出しを使って
ユークリッドの互除法を書く
再帰呼び出しの便利なところをもう一つ紹介しましょう。紀元前3世紀のギリシア数学の巨匠ユークリッド*7-6が考えた,最大公約数を求める方法,いわゆる“ユークリッドの互除法”をプログラミングしてみます。
ユークリッドの互除法の原理は,次の通りです。
a と b の最大公約数を GCD(a, b) と表す*7-7。 「a > b > 0」 とし,a を b で割ったときの余りを「r >= 0」とする。このとき,「GCD(a,b) = GCD(b,r)」が成立する。
ハノイの塔に引き続き,これも難しそうですね。でも心配いりません。再帰呼び出しを使えば,このプログラムも簡単に実装できるのです。
リスト6のgcdrが,再帰呼び出しを使って最大公約数を求める関数です。yが0になるまで,上記の公式を繰り返します。リスト6を実行し,57と9の最大公約数3を求めた結果が図7です。ちなみに最大公約数が求まると最小公倍数(lowest common multiple)も簡単に求めることができるので,
(x * y)/gcd=57 × 9 ÷ 3
リスト6では最小公倍数171も求めています。
#include
int gcdr(int x, int y);
int main()
{
int x,y,gcd;
printf("最大公約数と最小公倍数を求める1番目の数:");
scanf("%d",&x);
printf("最大公約数と最小公倍数を求める2番目の数:");
scanf("%d",&y);
gcd = gcdr(x,y);
printf("%d と%d の最大公約数は%d ?n",x,y,gcd);
printf("%d と%d の最小公倍数は%d ?n",x,y,(x * y)/gcd);
return(0);
}
int gcdr(int x, int y)
{
if (y == 0)
return x;
return gcdr(y, x % y);
}
リスト6●再帰呼び出しを使ってユークリッドの互除法を実装したプログラム
 図7● リスト6を実行したところ
図7● リスト6を実行したところ
このように再帰呼び出しをうまく使えば,冗長になりがちなプログラムを簡潔に書くことができます。しかし,再帰呼び出しも万能ではありません。取り扱う課題によってはかえって非効率な場合もあります(カコミ記事「フィボナッチ数列の場合は再帰呼び出しを使うべきではない」を参照)。要は,ケースバイケースで使うのが得策というわけです。
フィボナッチ数列の場合は再帰呼び出しを使うべきではない 再帰呼び出しを使うと,ハノイの塔のプログラムのように,ロジックを単純にすることができます。しかし,プログラムを単純にすることは,必ずしも処理の効率化とは比例しません。再帰呼び出しを行うことで非効率な処理を作成してしまう場合もあります。その代表的な例がフィボナッチ数列でしょう。
フィボナッチ数列とは,13世紀のイタリアの数学者フィボナッチ(Leonald Fibonacci)が,次のような問題を解くにあたって考え出したと言われています。
一つがいのウサギは,産まれて2カ月目から毎月つがいのウサギを産む。つがいのウサギは1年の間に何つがいのウサギになるか?
つがいのウサギは,最初の何カ月かはゆっくり増えるように思えますが,1年もたたないうちにとんでもない数になります(表A)。
 表A●経過月とつがいのウサギの数
表A●経過月とつがいのウサギの数
表Aをよく見ると,フィボナッチ数列の規則性がわかりますね。ある項(n)の値は「(n-1)の値と(n-2)の値を足したもの(隣り合う二つの数を足すと次の数になる)」で表現できるのです(ただしnが3以上のとき)。この規則をもとに再帰呼び出しを使ってプログラムしたのが,リストAのFibo_r関数です。リストAには,再帰呼び出しを使わずに,単純にループ処理だけでフィボナッチ数列を求めるFibo関数も実装しました。Fibo_r関数では呼び出された回数をcount++でカウントアップ,Fibo関数ではループ回数をカウントアップしています。
#include
int Fibo_r(int n);
int Fibo(int n);
int count;
int main()
{
int n;
printf("何ヶ月後ですか:");
scanf("%d", &n);
count=0;
printf("フィボナッチ数(兎のつがいの数)は%d \n", Fibo_r(n+1));
printf("再帰での計算回数は%d\n", count);
count=0;
printf("フィボナッチ数(兎のつがいの数)は%d \n", Fibo(n+1));
printf("ループでの計算回数は%d\n", count);
return 0;
}
int Fibo_r(int n)
{
int fibo;
count++;
switch (n) {
case 1:
case 2:
fibo = 1;
break;
default:
fibo = Fibo_r(n - 1) + Fibo_r(n - 2);
break;
}
return (fibo);
}
int Fibo(int n)
{
int x,y,z,i;
x = 1;
y = 1;
for (i=3;i<=n;i++) {
count++;
z = x + y;
y = x;
x = z;
}
return (x);
}
リストA●フィボナッチ数列を使ったプログラム。36より大きな数を指定してはいけない リストAを実行してみましょう(図A)。11カ月経過後のつがいのウサギの数を求めるのに,再帰呼び出しの処理では287回関数が呼び出されています。一方,再帰呼び出しを使わずにループ処理した場合では,同じ答えを得るのにループを10回まわせば済んでいますね。どちらが効率的か言うまでもありません。フィボナッチ数列は再帰処理で計算すべきでない代表的な数と言えるわけです(このプログラムに大きな月数を与えないでください。ウサギは猛烈なスピードで増えていきますから…)。ちなみに,花びらや葉の数など植物に関係のある数は,フィボナッチ数である場合が多いことが知られています。
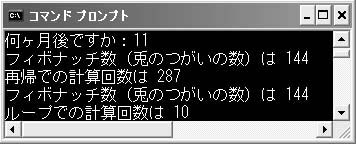 図A●リストAを実行したところ
図A●リストAを実行したところ
参照渡し(モドキ)の実装の仕方
さて,いよいよ冒頭で紹介した,ポインタを使った参照渡し(モドキ)について説明しましょう。
ポインタを使った参照渡し(モドキ)は,「関数は複数の引数を受け取れるが返せる値は一つだけ」という基本を,ちょっと拡張したいときに役に立ちます。
何はともあれリスト7を見てください。リスト6と同様に,最大公約数と最小公倍数を求めるプログラムです。ただし,main関数で最大公約数を入れる変数gcdと最小公倍数を入れるlcmを宣言しているところが,これまでのプログラムとは違いますね。
 リスト7●ポインタを使った参照渡し(モドキ)のプログラム
リスト7●ポインタを使った参照渡し(モドキ)のプログラム
(1)の部分でgcd_lcm関数に,入力された二つの整数(57と9)とgcd変数のアドレス,lcm変数のアドレスを引数として渡しています*7-8。gcd_lcm関数ではint *pgcd, int *plcmとポインタで二つの変数のアドレスを受け取っています(図8)。
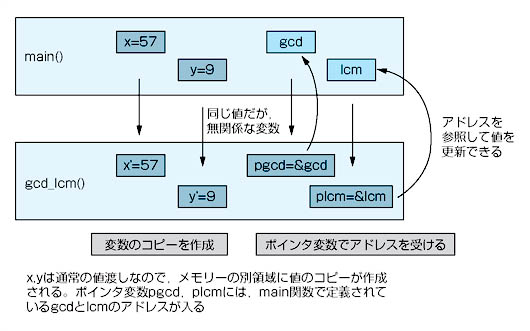 図8●リスト7におけるgcd_lcm関数の動き
図8●リスト7におけるgcd_lcm関数の動き
(2)で最大公約数を求めるgcdr関数を実行し,返ってくる最大公約数をポインタpgcdが指すアドレスに代入しています*7-9。次に(3)でポインタplcmが指すアドレスに最小公倍数を入れています。このようにポインタを使うことで,他の関数で宣言された変数の中身を更新できるようになります。これがポインタを使った参照渡し(モドキ)の効果です。
二つの変数の値を入れ替える
実は,リスト6,7のプログラムはユークリッドの互除法の原理をきちんと守ってはいません。「a > b > 0」の部分です。b(2番目の数)がa(1番目の数)より大きくても,そのまま処理が実行されます。その場合,計算回数が増えるだけで,同じ答えを取得できるので見逃しても構わないのですが,ポインタによる参照渡し(モドキ)を使えば,二つの値を入れ替えられます。
具体的には,リスト7の3行目「void gcd_lcm(int x, int y, int *pgcd, int *plcm);」の後に「void irekae(int *ph, int *pl);」,10行目のscanf関数の後ろに「irekae(&x, &y);」と記述し,次のirekae関数を追加します。
void irekae(int *ph, int *pl) {
int tmp;
if (*pl > *ph ) {
tmp = *pl;
*pl = *ph;
*ph = tmp;
}
}
irekae関数に変数xとyのアドレスを渡し,yがxより大きい場合にtmpを介して変数の中身を入れ替えています。この処理を値渡しで考えると面倒ですが,ポインタを使うと変数の値の入れ替えが簡単に行えます。
今回は,C言語初心者の方には,ちょっと難しかったかもしれませんね。特に再帰呼び出しはざっと読んだだけでは,なかなか実感がわかない処理です。関数が自関数を呼び出す様子を引数の値を追いながら,紙に書いてみると理解しやすいでしょう。実際,数学の公式の目的がわからなくても,なぜそうなるのか公式自体がおもしろいことは結構あります。ぜひ,頭の体操だと思って,その不思議を味わってみてください。それでは,また!
第8回 構造体でデータをスッキリと扱う
はやいもので本連載も,もう第8回目です。前々回,前回とも,C言語の初心者の方には,少し手ごわい内容だったかもしれません。
今回は一度,入門レベルに戻り,「構造体」というものは何かから説明をはじめます。今回と次回の2回で,構造体の基本,構造体を使うと何が良いのか,動的にメモリーを確保する方法,線形リスト*8-1へと解説を進めていきます。今回はロール・プレイング・ゲーム(RPG)のようなプログラムも作ってみますので,はじめて本連載を読む方やC言語の入門は勉強したけど構造体やリストまではやらなかったという方も,ぜひ最後までお付き合いいただけたらと思います。
構造体とは関連する情報の固まり
さて,ずばり構造体とは何でしょう? 構造体とは,C言語において組み込み済みの型*8-2を複数組み合わせて,新しい型を作る仕組みのことです。複数組み合わせるというと「配列」が頭に浮かびますが,構造体は配列とは違います。
例えば,int a[6]という配列のコードは,int型の大きさの記憶領域を複数個確保するイメージになります(図1(a))。int a[6]には整数値を六つ記憶することができますね。つまり同じ製品を整然とダンボールに詰めていくのが配列です。
これに対し,構造体は複数種類の型を組み合わせて,一つの固まりとして扱えるようにするものです。違う製品を数種類詰め合わせたギフトセットのようなものをイメージするとわかりやすいでしょう(図1(b))。
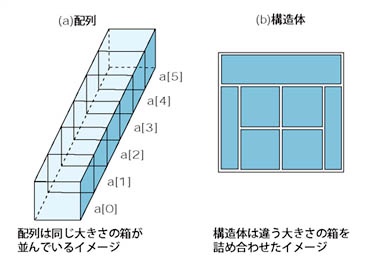 図1●配列と構造体のイメージの違い
図1●配列と構造体のイメージの違い
もう少しプログラムっぽく考えてみましょうか。例えば,スポーツによる健康なダイエットを目指す「やせよう会」という会の会員情報を管理するプログラムを作成したいとします。会員のデータとして,会員NO,ニックネーム,性別,身長,体重,連絡先電話番号を記憶させたいときに,組み込み型だけを使って表現すると,リスト1のようにいくつも変数を宣言することになるでしょう。変数no,変数nickname,変数weightの間にどんな関係があるのかは,ソースコードを見ただけではわかりません。同一人物の情報であることを示す手掛かりがないからです。
int no;
char nickname;
char sdist;
int age;
float height;
float weight;
char telno[14];
しかし,人物にしてもモノであっても,それを表現する場合には複数の関連する情報(属性)が必要になるのは当然です。車を表すなら,車種,排気量,何年式かなどの複数の情報が必要になりますよね。そのようにモノを表現するための,関連する情報を一つの固まりとして扱えるようにするC言語の仕組みが構造体なのです。
構造体型の宣言の仕方
構造体を使うと,リスト1のようにバラバラな情報を,ある人物を表す情報としてグループ化できます。具体的に見てみましょう。リスト2の(1)が,「構造体型(structure type)」の宣言のサンプル・コードです。structキーワードを使って,次のように構造体型を宣言しています。
struct 構造体型名(構造体タグ名) {
型名 識別子;
型名 識別子;
…
}
 リスト2●構造体を使ったサンプル・プログラム
リスト2●構造体を使ったサンプル・プログラム
構造体型の宣言とは,複数の既存の型を組み合わせて,新しい「型」を作ることです。この時点では,memberというヒナ型(テンプレート)が作成されただけで,実際にメモリー上に存在する構造体型変数を宣言するには,
struct member mem1;
とします。これでstruct member型の変数mem1が使用可能になります。リスト2の(2)のように中カッコでくくって変数の宣言と同時に初期化することもできます。構造体の中の項目(この例だとnoやnicknameなど)をメンバーと呼び,メンバーを参照するにはリスト2の(3)のようにドット演算子を使います。つまり,mem1.nicknameとすれば,構造体型変数mem1のnicknameメンバーを参照するわけです。実際にリスト2を実行すると図2のようになります。初期値として与えた値を表示した後,体重(weight)だけを変更して,構造体のメンバーを再表示していますね。
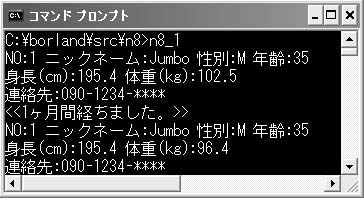 図2●リスト2を実行したところ
図2●リスト2を実行したところ
typedefキーワードで
構造体型に名前を付けられる
新しい型を作ったといっても,「int no;」と変数を宣言するのと違い,「struct member mem1;」という宣言は説明っぽくて,いかにも後から付け足した感じがします。
そこでC言語では,typedefというキーワードを使ってデータ型名をプログラマがわかりやすい名前に定義し直すことができます。この機能を使って構造体型にシンプルな名前を付けてみましょう。
リスト3はtypedefを使って,struct member型にmem_tという名前を付けています。中カッコを閉じた後の「mem_t」の部分です。これで,リスト2の(2)の部分を「mem_t mem1=~(以下同じ)」とすれば,構造体型変数を宣言できるようになります。
typedef struct member{
int no;
char nickname[20];
char sdist;
int age;
float height;
float weight;
char telno[14];
} mem_t;
リスト3●リスト2の構造体の定義をtypedefを使って変更したコード
構造体の便利なところ
次に,構造体を使うとバラバラな変数をいくつも使うより便利なのだという点を紹介しましょう。構造体型は複数の変数によって構成された型なので,プログラミングのうえでは,多くの情報を一度で操作できるというメリットがあります。
(1)構造体同士を代入できる
構造体は,同じ構造体型なら構造体ごと代入することができます。リスト4を見てみましょう。これは,(1)で本のタイトル,著者名,販売価格を構造体型でbook_t型変数として定義し,book_t型変数をbk1,bk2,bk3と三つ宣言して,bk1からbk2へ,bk1からbk3へとそれぞれコピーするプログラムです(図3)。
 リスト4●構造体同士を代入するプログラム
リスト4●構造体同士を代入するプログラム
 図3●リスト4を実行したところ
図3●リスト4を実行したところ
ポイントはコピーの仕方です。bk1からbk2へのコピーは,タイトルや著者名ごとにメンバー単位にコピーしていますね(リスト4(2))。この例ではメンバーが三つしかありませんが,メンバーの数が多くなればなるほど,一つひとつメンバーの値を代入するのが面倒になることが予測できるでしょう。
一方,bk1からbk3へのコピーは構造体まるごとのコピーです(リスト4)。こちらは,たったの1行で済んでいます。(2)のように,文字型の配列のコピーには通常はstrcpyなどの標準文字列関数を使わなくてはならないのですが,構造体のメンバーなら簡単にコピーできるのです。便利ですね。
(2)構造体を関数の引数として渡せる
C言語では関数への引数が値渡し(pass by valueまたはcall by value)であることは,本連載で何度か説明しました。呼び出された関数側では,メモリー上に作成された値のコピーを扱うことになるのでしたね。構造体を引数として渡した場合も,各メンバーのコピーが作成されます。
リスト5は,指定した文字で画面上に四角形を描画するプログラムです(図4)。構造体型変数rect1のメンバーは,描画する行数を示すline,桁数を示すcol,文字を指定するmojiの三つ(1)。(2)のように構造体を引数として渡すことで,一つひとつ変数として渡すよりも,スッキリとしたコードになっています。
 図4●リスト5を実行したところ
図4●リスト5を実行したところ
また,文字で画面に四角形を描画するときは行数と桁数でコントロールすればよいということが,構造体型を定義する時点で明確になっているという点も重要なポイントです。構造体型のメンバーを決めていく時点で,プログラムの構造をかなり見通すことができるのです。
 リスト5●指定した文字で四角形を描くプログラム
リスト5●指定した文字で四角形を描くプログラム
(3)構造体へのポインタを引数にできる
変数のアドレスを関数に渡し,ポインタで扱えば参照渡しのような操作,つまり呼び出し元の変数の値を呼び出された関数側で変更できることは前回説明した通りですが,構造体でも同じことができます。構造体のアドレスを引数に渡し,ポインタとして受け取れば,構造体の各メンバーの値を変更することができます。
次のサンプルは,少し楽しめるようなものにしてみました(なんといっても,今月の本誌の発売日はクリスマスイブですからね!)。二人の魔法使いが互いに魔法をかけあうという,ロール・プレイング・ゲーム(RPG)のようなプログラムです。
リスト6を見てください。魔法使い構造体型magi_tを定義し(1),魔法使い1と魔法使い2をma1,ma2として宣言しています(2)。この二人の魔法使いを戦わせるのがゲームの内容です。
 リスト6●簡単なロール・プレイング・ゲームのプログラム
リスト6●簡単なロール・プレイング・ゲームのプログラム
構造体の各メンバーは,name[30]が魔法使いの名前,powerがパワーで,魔法による攻撃を受けると減少します。魔法使いは3種類の魔法(1:ぐったりさせる,2:しょんぼりさせる,3:がっかりさせる)をかけることができます。mgpower1から3はそれぞれの魔法の力で,vsmg1から3はその魔法に耐える力(魔法耐力)です(図5)。二人の魔法使いは,互いに相手の魔法力と魔法耐力はわかりません。攻撃を行うfight関数(3)では,あてずっぽうで効きそうな魔法をかけることになります。魔法力が魔法耐力を上回っていれば魔法が効き,相手のpowerが10ダウンします。fight関数では構造体型のポインタを引数に使っているので,「ma2->power -=10」とすることで,相手のパワーを変化させることができるのです(図6)。
 図5●リスト6のプログラムのイメージ
図5●リスト6のプログラムのイメージ
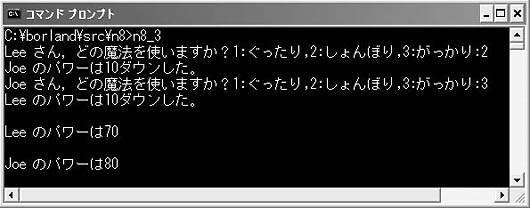 図6●リスト6を実行したところ
図6●リスト6を実行したところ
ここで,見慣れない演算子が登場していますね。「->」はアロー演算子といい,構造体型変数にポインタからアクセスする場合に使うことができます。「*(アスタリスク)」や「.(ドット)」を使って表現することもできるのですが,その書き方だと面倒なので,ma2->powerとアロー演算子で簡潔に記述できるようになっているのです。
(4)構造体に配列を含められる
これまでも構造体のメンバーとしてchar型の配列を使ってきていますが,構造体には配列を含めることができます。リスト6には同じ項目がmgpower1~3,vsmg1~3と繰り返し存在していますので,リスト7の(1)のようにこれを配列にしてみましょう。構造体のメンバーをmgpower[3],vsmg[3]と配列にしています。これによりfight関数の中では,魔法力と耐力を添え字で操作できるようになりました(リスト7の(2))。ソースコードが簡潔になりましたね。
データ構造をスッキリさせれば,それを処理するコードもスッキリすることが多いのです。
 リスト7●構造体に配列をいれてリスト6を修正したコードの一部
リスト7●構造体に配列をいれてリスト6を修正したコードの一部
構造体を使いこなしてもっとゲームらしくする
では今回のまとめとして,リスト7のプログラムをもっとRPGらしく修正してみましょう。魔法使いが4人登場できるようにして,4×4の碁盤の目の上を歩きまわり,出会ったら魔法をかけあうという設定に変えてみたいと思います。図7のようなイメージです。プログラムはリスト8のようになります。
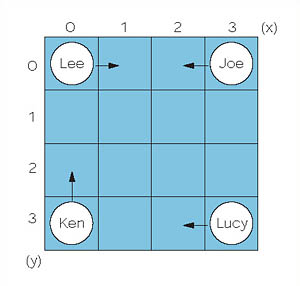 図7●4人の魔法使いが戦う碁盤
図7●4人の魔法使いが戦う碁盤
「出会ったら」という条件を実現するには,各魔法使いに碁盤の目の現在位置を持たせる必要があります。struct magicianにx座標とy座標を記憶するメンバーを直接追加しても構わないのですが,構造体はネスト(入れ子に)できるので,x座標とy座標だけを記憶する構造体型をpos_tの名前で定義し(1),magician構造体の中でメンバーに指定しています(2)。構造体が複雑になりすぎるときは,別の構造体に分けてネストすれば,データの構造がハッキリするでしょう。
 リスト8●4人の魔法使いが対戦するプログラム
リスト8●4人の魔法使いが対戦するプログラム
また,魔法使いを何人も登場させるには,構造体を配列にします。magi_t型の要素を四つ持つ配列を「magi_t ma[4]」で宣言しています(3)*8-3。構造体を使わずに名前やパワーをそれぞれ配列にして,name[0]のパワーはpower[0]と,添え字で各配列の要素を関連付けることもできますが,構造体を使って魔法使いごとに属性をまとめる方が自然であり,わかりやすいのは言うまでもないでしょう。
main関数のwhileのループの中を順に見ていきましょう。まず,各魔法使いを移動させるmove関数を呼び出し(4),魔法使いを移動させた後,誰かと誰かが出会ったかをチェックをするmeet関数を呼び出しています(5)。move関数は現在位置と,移動できない方向を表示して,移動方向の入力をscanf関数で受け付けます(6)*8-4。移動可能な方向が入力された場合は位置情報を変更し,変数movedに1を代入してreturn文で返しています(7)。そして,move関数の戻り値が,真の場合(0ではない場合)にmeet関数以下を呼び出すようにしています。ここで注意してほしいのは,自分自身とぶつかったと判断しないようにすることです。そこで,「if (i!=j)」として両者の添え字が異なる場合のみを処理対象にしています。
meet関数では,両者のxの座標とy座標が一致した場合に1を返すようにしています(8)。ネストした構造体のメンバーを参照するにはma1.pos.xと記述します。出会ったときに(meet関数が真のときに)呼び出されるfight関数の内容はリスト7と同じです。
構造体の話からはそれるのですが,if文やswitch文の中で何も実行する処理がない場合,皆さんならどうしますか? もちろんコード上は何も記述しなくていいのですが,筆者は,「/* 何もしない */」のようにコメントを入れることをお勧めします。何も記述していないと,しばらくしてからそのプログラムを読むことになった人が(それは数カ月後あるいは数年後の自分かもしれません),そこに何も書いてないのが正しいのか,間違って削除されたのか不安を抱くためです。
さて,4人分の移動処理が終わったら,「続けますか?」と表示して入力を待ちます。「1:続ける 0:終了」と表示する部分です(9)。実際には0が入力されるまで処理を繰り返します。0が入力されたら,showall関数を呼び出して,配列の各要素のメンバー値をすべて表示させます(図8)。
 図8●リスト8のプログラムを終了したところ
図8●リスト8のプログラムを終了したところ
move関数とfight関数には,配列の要素である構造体のアドレスを渡し,meet関数,showall関数には構造体そのものを渡しています。メンバー値を変更する必要のある場合にはポインタを使っているのですね。ネストしたメンバーにポインタからアクセスする場合の書き方は「ma->pos.x」であることも覚えておいてください。
さあ,ここまでできれば,あとはアイデア次第。「パワーアップ・ドリンクを飲むとパワーが上がる」「巻物をゲットすると魔法力が上がる」「修行をすると耐力が増す」…などとプログラムを拡張していくと楽しいでしょう。とはいえ,きりがないので,この記事ではこのあたりでやめておきたいと思います。続きはぜひ,皆さんで挑戦してください。
構造体を使うと,データをスッキリ/ハッキリ表現できることがおわかりいただけたと思います。次回は動的にメモリーを確保する標準関数を使って,必要に応じて新しい構造体型変数を作っていく方法と,構造体に次の構造体へのポインタを含めることで,線形リストを作成するお話に進んでいきたいと思います。ぜひ,お見逃しなく!
第9回 動的なメモリーの確保とリスト処理
前回は構造体の配列を使って,簡単なロール・プレイング・ゲームを作ってみました。お楽しみいただけたでしょうか? 今回は構造体を発展させていきます。動的にメモリーを確保して構造体を生成していく方法,そして線形リストへと解説を進めます。C言語で本格的なプログラムを記述するためには,ぜひ覚えておいてほしいテクニックです。最後までお付き合いください。
動的なメモリーの確保が必要な理由
まず,動的なメモリーの確保とは何か,またなぜそのようなテクニックを使う必要があるのかを説明しましょう。
前回は構造体の「配列」を扱いましたが,配列の不便なところは,要素の数を変化させることができない点にあります。使わなくてもメモリー上に場所をとるし,足りなくなっても追加するすべがありません。
学生寮の夕食をイメージしてみましょう。配列というのは,「今日もたぶん,100名くらいが夕食を食べにくるだろう」と予測して食事の用意をするようなものです。80名しか来なかったら,余ってもったいないですが,100名分きっかりしか作らないと,101番目に来た人には「ごめん,もうなくなった」と断るしかありません。足りなくなってはどうしようもないので,通常は予想した数より,いくらか余裕をみた要素数の配列を用意します。
要素数を予想できる場合はそれでいいでしょう。しかし,推測しにくいものや上限を決めたくない種類のデータもありますね。例えば,何かの会や組織の会員数です。当初の会員は20名でも,目標は2000名となると配列では無駄が多すぎます。そんなときに「動的なメモリーの確保」というテクニックを使えば,その都度,適切な量のメモリーを取得して使用することができます。
リスト1は,配列を使って5人分のテストの点数を入力してもらい,5人の点数を表示しながら合計と最高点を求め,最高点と平均を表示するプログラムです。一方リスト2は,同じ処理を「動的なメモリーの確保」を使って行うプログラムです(図1)。何人分のデータを入力するかとたずねてから,メモリー・ブロックを確保していますね。前もって夕食の予約を取ってから,作るようなものです。
#include <stdio.h>
#define NINZU 5
int main()
{
int tensu[NINZU];
int i;
int j=0;
int max=0;
double goukei=0;
for (i = 0; i < NINZU; i++) {
printf("%d番目の人の点数は:",i + 1);
scanf("%d",&tensu[i]);
}
for (i = 0; i < NINZU; i++) {
printf("%d番目の人の点数は%dです\n",i + 1,tensu[i]);
goukei+=tensu[i];
if (tensu[i] > max) {
max=tensu[i];
j=i;
}
}
printf("最高点は%d番目の%dです\n",j+1,max);
printf("平均点は%.2fです\n",goukei / NINZU);
return(0);
}
リスト1●配列を使って5人の成績を表示するプログラム
 リスト2●リスト1のプログラムを「動的なメモリーの確保」を使って人数を設定できるように修正したプログラム
リスト2●リスト1のプログラムを「動的なメモリーの確保」を使って人数を設定できるように修正したプログラム
リスト2は,malloc関数を使ってメモリー領域(メモリー・ブロック)を確保し(1),ポインタを使って操作している点がリスト1とは異なります。mallocは指定したサイズのメモリー領域を確保する関数で,確保できた場合,その領域の先頭へのポインタを返します。領域の確保に失敗した場合はNULLを返します(2)。\
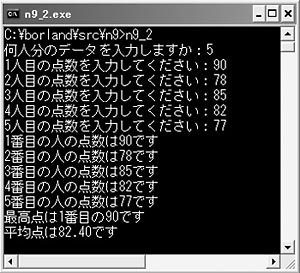 図1●リスト2を実行したところ
図1●リスト2を実行したところ
ここではっきり意識してほしいのは,配列は要素のデータ型と数を最初に決めて宣言するので,同じ型のデータを格納できる箱を複数作成するイメージですが(図2の(a)),動的なメモリーの確保はメモリーのかたまりを自分のプログラムで自由に使える領域として確保しているだけ,という点です(図2(b))。動的にメモリーを確保した関数が返すメモリー領域のアドレスを,「(int )」のようにint型へのポインタにキャスト(型変換)して,ポインタでメモリーを区切って使っているのです。サクどりされたマグロを買ってきて,都合の良い大きさに切って使うようなものですね。「(ninzusizeof(int)」で確保した領域のポインタを「(char *)」でキャストして,char型の値を20個入れる領域として使うこともできます*9-1。
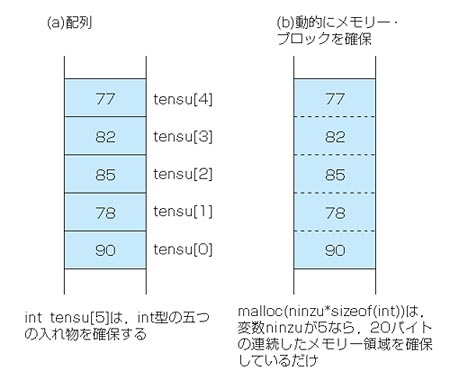 図2●リスト1とリスト2でメモリーを確保したときのイメージ
図2●リスト1とリスト2でメモリーを確保したときのイメージ
連載の4回目で説明したように,メモリーはヒープ,データ・セグメント,コード・セグメント,スタック3の四つの部分にエリア分けされています。関数の引数やローカル変数はスタックに格納されるのでしたね。一方,malloc関数などで,動的に確保するメモリー領域はヒープに作成されます。ヒープに作成されるということは,ローカル変数とは異なり,プログラムのどの部分からでも参照できるということになります。
動的なメモリーの確保に使用する四つの関数
では次にリスト3を使って,動的なメモリーの確保に使用する標準ライブラリ関数を見ていきましょう。malloc,calloc,realloc,freeの四つです(表1)。これらの関数を使う場合は,リスト3の(1)のようにstdlib.hをインクルードすることを忘れないでください(インクルードしないとコンパイル・エラーになります)。
 リスト3●動的なメモリーの確保に使う関数の使用例
リスト3●動的なメモリーの確保に使う関数の使用例
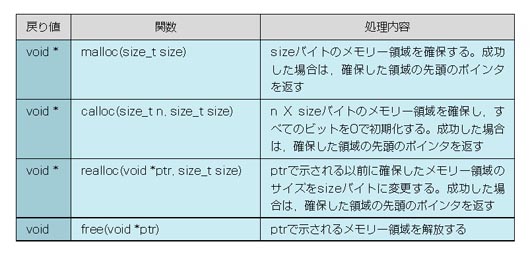 表1●動的なメモリーの確保に使用する関数。ヘッダー・ファイルstdlib.hをインクルードする必要がある。size_tはヘッダー・ファイルの中で,unsigned intと宣言されている*
表1●動的なメモリーの確保に使用する関数。ヘッダー・ファイルstdlib.hをインクルードする必要がある。size_tはヘッダー・ファイルの中で,unsigned intと宣言されている*
(2)のmalloc関数はリスト2でも出てきたように,メモリー領域を確保する関数ですが,実はcalloc関数を使っても同じことを実行できます。malloc関数は引数が一つなので「100*sizeof(char)」のように指定しましたね。一方calloc関数ではこの引数を二つにばらして,(3)のように「calloc(100,sizeof(char))」(100個,char型の大きさのメモリーを)という具合に指定します。calloc関数は,確保したメモリー領域のすべてのビットを0で初期化するという点でmalloc関数とは違います。
どちらの関数を使うにせよ動的なメモリーの確保を行う場合に気を付けなければいけないのは,ヒープは要求する大きさのメモリー領域を必ずしも確保できるわけではないということです。リスト2や3で,NULLポインタが返ってきた場合の処理を記述してあるのはそのためです。
動的に確保したメモリーは,配列とは異なり後で変更できます。それがrealloc関数を使ってメモリー領域の大きさを変更している(4)の部分です。realloc関数を使うときの注意点は,先に確保した領域のサイズを大きくしようとした場合に,現在の領域の先頭アドレスから連続して,必要な領域を確保できないケースがあるということです。
malloc関数を2回実行して,二つのメモリー領域が並んでいる様子をイメージしてください。p1が指す領域とp2が指す領域は長屋のようにきっちり隣り合ってメモリー上に配置されているわけではありません。しかし,p1が指す領域を100バイトから200バイトに広げようとした場合,p2が指す領域とぶつかってしまい,連続して必要な領域を確保することができないかもしれません。このような場合,realloc関数はp2が指す場所を避けて,連続して200バイトのメモリー領域を確保できる場所でメモリー領域を確保しようとします。そのとき,先頭のアドレスが変わってしまう場合があります(図3)。
 図3●リスト3の(4)でp1のメモリー領域を200バイト広げた結果,p1の先頭アドレスが変わってしまった
図3●リスト3の(4)でp1のメモリー領域を200バイト広げた結果,p1の先頭アドレスが変わってしまった
また,realloc関数が返すポインタをいったん,ptという別のポインタ変数に代入してからp1に入れているのは,reallocに失敗してNULLが返ってきたときに,もとのp1の値が失われてしまうのを避けるためです。いままで使っていたメモリー領域のアドレスがわからなくなると,free関数で解放することもできませんからね。realloc関数を使う場合は,このようなテクニックが必要なことを覚えておいてください。
データを数珠つなぎにしていくのがリスト処理
さて,いよいよ線形リストに話を進めましょう。データがある順序にしたがって並んでいるデータ構造を「リスト」と呼びます。「線形リスト」や「リンクリスト」と呼ばれるものがシンプルなリストの代表格です。線形リストはデータとポインタで構成されるノード(node)と呼ばれる要素によって構成され,ポインタは次のノードを指し示します。最初のノードを先頭ノード(head node),最後のノードを末尾ノード(tail node)と呼び,最後のノードだけはポインタ値がNULLになります。線形リストの利点はデータの挿入や削除が簡単なことです。各ノードは構造体で,通常malloc関数などで動的にメモリーを確保して作成します。
とはいえ,いきなり動的なメモリーの確保を使ってリスト処理を作成していくのは難しいので,まず構造体の配列で考えてみましょう。
例として,何かのクラブの電話連絡網を取り上げます。リスト4では,name[15],telno[15]の二つのメンバーを持つ構造体型にtel_listという名前を付け(1),club[10]で10人分の配列として宣言しています。4件のデータで初期化しているので(2),実行すると表2のように4人分の名前,電話番号が構造体の配列に登録されることになります*9-2。
 リスト4●構造体を使って連絡網のデータを格納して表示するプログラム
リスト4●構造体を使って連絡網のデータを格納して表示するプログラム
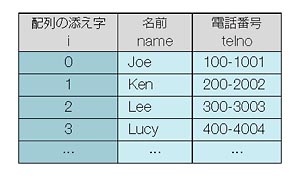 表2●リスト4で格納するデータ
表2●リスト4で格納するデータ
実はこの電話連絡網,名前のアルファベット順に電話連絡しなくてはならないのですが,現在の仕様では,「club[i]」の「i」という配列の添え字の順番に表示するようになっています。では,新たに「Johnが入会する」ことになったら,どうしたらいいでしょう?
アルファベット順に並べ替えるには,Joeの後にJohnが入るようにKen,Lee,Lucyを一つずつ後ろにずらさなければなりません。10名くらいならたいした手間ではありません。しかし,クラブの会員が数百名だったらいちいちそんなことをするのは非効率的ですね。さらに,途中で誰かが退会したらその人を削除して,連絡網がつながるように今度は前方向に一つずつずらす必要も出てきます。単に配列の順番にデータを格納しただけでは,データの挿入や削除に弱いデータ構造になってしまうわけです。
もっとうまい方法はないものか。ということで考えたのがリスト5です。構造体のメンバーに,「次の要素を示す添え字(nidx)」を追加しました。次に電話する人の添え字を保持していれば,電話する順にデータが並んでいる必要はないので,表3のようなランダムな順序でデータを登録することができます。
#include <stdio.h>
#include <string.h>
typedef struct telephoneNumber_list {
char name[15];
char telno[15];
int nidx;
} tel_list;
int main()
{
int pos;
tel_list club[11]={
{"dummy","",2},
{"Lee","300-3003",4},
{"Joe","100-1001",3},
{"Ken","200-2002",1},
{"Lucy","400-4004",-1}
};
pos=club[0].nidx;
while (pos != -1) {
printf("%s %s\n",club[pos].name,club[pos].telno);
pos=club[pos].nidx;
}
return 0;
}
リスト5●リスト4のプログラムに添え字を追加して並べ替えるようにしたプログラム
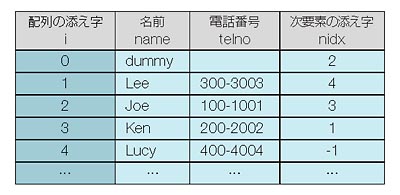 表3●データに,「次の要素」を示す「添え字(nidx)」を追加した
表3●データに,「次の要素」を示す「添え字(nidx)」を追加した
ポイントは,アルファベットの最も前の人に最初に電話できるように,先頭にdummy(ダミー)データが入っている点です。dummyのnidxには一番最初に電話する人の添え字を入れます。また,最後に電話を受けるLucyのnidxには「-1」を入れます。-1を「もう次はない」という印に使っているのです。
リスト5のプログラムを実行すると図4のようになります。nidxをposに代入し,添え字とすることでアルファベット順に表示させることができるというわけですね。
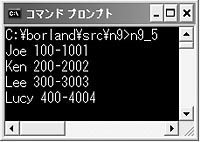 図4●リスト5を実行したところ
図4●リスト5を実行したところ
ここで図5のように電話をかける順にデータを横に並べてみましょう。データの構造が,前述した線形リストになっていることがわかりますね。dummyを先頭ノードとして各ノードがnidxでつながっています。
 図5●リスト5のプログラムのデータは線形リストになっている
図5●リスト5のプログラムのデータは線形リストになっている
このように「次はどこ」を示すポインタ*9-3を配列に持たせておけば,会員が増えるたびに,配列全体を移動させる必要はなくなります。図6のように新会員が入会した場合は,配列の末尾に追加し新会員に電話する人のnidxを変更すればよいからです。
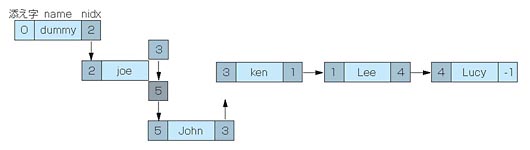 図6●途中でデータを追加しても修正が最小限に済む
図6●途中でデータを追加しても修正が最小限に済む
配列を使ってリスト処理を実装する
では,実際にデータの追加と登録したデータを削除するケースを考えてみましょう。
リスト6を見てください。リスト5の名簿プログラムをバージョンアップして,会員の追加/表示/削除を選択できるようにしたものです。やや長いソースコードなので難しい感じがするかもしれませんが,main,addnode,deletenode,showlist,showarrayの五つの関数があるだけです。関数ごとに考えるとそんなに複雑なことをやっているわけではありません。main関数の処理はメニュー選択だけです。1が入力されるとノードの追加を行うaddnode関数を呼び出し,2が入力されるとノードをnidxでトレースして表示するshowlist関数を呼び出し,3が入力されるとノードを一つ削除するdeletenode関数を呼び出します。0が入力されるとwhileループを抜けて,showarray関数で配列の中にどのようにデータが格納されているかを表示してプログラムを終了します。showlist関数,showarray関数はこれまでのサンプル・プログラムの関数とほぼ同じ内容なので説明の必要はないでしょう。
 リスト6●会員名簿の追加/表示/削除を行うプログラム
リスト6●会員名簿の追加/表示/削除を行うプログラム
addnode関数に注目してください。まず(1)の宣言と初期化で,club構造体配列にdummyのデータを1件登録し,nidxには「-1」を設定しています。(3)のforループで配列中の空いている場所を探しています。ここでは,nameの文字数が0だと空いていると判断するためにstrlen関数*9-4を使い,配列の要素数(NINZU)以下で空いている場所があったら,変数idxに添え字iの値を代入しています。idxが初期値の0のままだと「配列がいっぱい」だと判断します。
次に,名前と電話番号の入力をname配列とtelno配列で受け取り,(4)のwhileループに進みます。変数posが「-1」ではなく,かつ入力された名前がclub構造体配列の添え字posで示される名前よりも大きければ,ループを繰り返してリストをたぐっていきます*5。
posには(2)でdummyデータのnidx(=-1)を代入しているので,最初にデータを追加するときは,すぐwhileループを抜けます。図7の(a)の状態です。このとき,配列中の格納すべき場所の添え字であるidxは1であり,前のデータの格納場所を示す変数prevは0です。
 図7●リスト6の実行の様子
図7●リスト6の実行の様子
「Lee」という名前を登録したときのことを考えてみましょう。(5)以降の代入でdummyのnidxに1が入り,club[1]のnameにLeeが,telnoにLeeの電話番号が入り,ここで連絡網は終わりですから,club[1]のnidxには「-1(pos)」が代入されます。図7の(b)の状態です。
次に「Joe」を追加するときは, dummyのnidxは1なのでposは-1ではありませんが,club[pos]のname(=Lee)はJoeより大きいのでwhileループを抜けます。このとき,idxは2,prevは0,posは1ですから,図7の(c)のようにデータが格納されます。「Ken」を追加するときはdummy→Joeと進み,Leeのデータを評価してwhileループを抜けます(図8)。
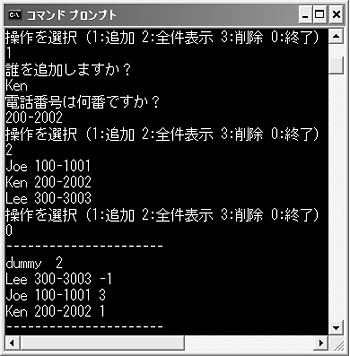 図8●3人登録して表示したところ
図8●3人登録して表示したところ
ノードを削除するdeletenode関数を見ていきましょう。今度は実行結果から考えていきます(図9)。あれ? Kenのデータを削除したのに,最後の全件表示でKenが表示されていますね。その代わり添え字は0になっています。実際にKenを消去して配列を詰めるような処理は非効率的なため,このようなプログラムにしました。図10のようにKenのnidxを無効にして,Kenの前であるJoeがLeeを指すようにすれば,論理的にリストから呼ばれることはなくなる(消去できる)わけですから,その方が手っ取り早いでしょう。本当に表示させたくなければ,添え字が0のデータは表示させないようにすればいいのです。
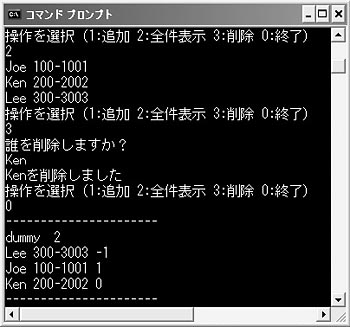 図9●1名削除したところ
図9●1名削除したところ
 図10●削除するときのイメージ
図10●削除するときのイメージ
リスト6の(6)以降が削除処理のコードです。nidxの値が-1になるまで,strcmp関数を使って入力された名前と同名のデータを探し,一つ前のnidxの値と自身のnidxの値を更新しています。
いかがですか? リスト処理を行うと効率のよいデータの挿入,削除ができることがおわかりいただけたのではないかと思います。
では,この構造体配列を使ったリスト処理に問題点はないでしょうか? よく考えてみると,
●追加できるデータの数がプログラムの作成時点で決まってしまうこと
●削除を繰り返していくと,論理的には存在しないが使えない領域がどんどん増えていくこと*9-6
の二つの問題点がありそうです。
そこで,これらの問題を解決するため,動的なメモリーの確保を使うわけです。動的なメモリーの確保を使ってノードを作成していけば,会員数の上限はヒープ領域の使用可能なメモリー量にのみ依存するようになります。また,削除はfree関数を使って確保したメモリー・ブロックを解放していけばよいので無駄がなくなります。誌面の都合でプログラム・コードを掲載できないのが残念ですが,日経ソフトウエアのWebサイトのダウンロード・コーナーに掲載しているので,ぜひそちらを参照してください。
大事なことは,構造体のメンバーに次のノードへのポインタを持たせることです。また,動的なメモリー確保によるリスト処理では,-1ではなく,NULLがリストの終わりを表すようにします。
リスト処理がわかると,いろいろなアプリケーションでどんな風にデータが処理されているかが少し推測できるようになってきます。皆さんもぜひ,サンプルを動かしてデータをどのように扱うべきか理解を深めてください。
次回はもっとアプリケーションらしいものを作れるようにファイル処理について説明します。どうぞお楽しみに!
第10回 定番の関数を覚えればファイル処理などカンタンだ
前回,前々回と構造体,動的なメモリーの確保,そして線形リスト処理と解説を進めてきました。連載10回目となる今回から2回にわたり,ファイル処理について解説します。今回の目標はファイル処理の基本を学んで自分に役立つプログラムを作れるようになることです。
ファイルとは「関連を持ったデータの集まりであり,ハードディスクなどの補助記憶装置に記録される」という説明は本誌の読者の皆さんには不要でしょう。まずは,ファイルの種類から見ていきます。
テキスト・ファイルとバイナリ・ファイル
ファイルには,テキスト・ファイルとバイナリ・ファイルの2種類があります。テキスト・ファイルは文字情報からなるファイルで,Windowsに付属しているメモ帳などのテキスト・エディタで編集できるファイルです。エディタで開いて見れば,人間が内容を理解できます*10-1。
これに対しバイナリ・ファイルは,バイナリつまり2進数のデータが羅列しているファイルで,16進数に変換してダンプ表示を行うプログラムを使って見ることができます。ただし,そこから人間が意味を見いだすことは困難です。
例えばC言語のソース・ファイル(拡張子が.cのファイル)はテキスト・ファイルですが,ソース・ファイルをコンパイル/リンクしてできるオブジェクト・ファイル(拡張子が.obj)や実行形式のファイル(拡張子が.exe)はバイナリ・ファイルです。人間には意味がわかりません。しかし,コンピュータにとっては意味のある2進数の並びなので,ソース・ファイル上で人間が指定した処理を実行形式のファイルから読み取り,実行することができるのです。ほかに画像データ,音声ファイル,それからワープロで作成した文書ファイルなども書式情報を含むのでバイナリ・ファイルです。
テキスト・ファイルとバイナリ・ファイルのほかに,どのようにデータを記録するかを意味するファイル編成の方法で,シーケンシャル・ファイルとランダム・ファイルという分け方があります。C言語の場合,それぞれの記録方法に違いがあるわけではないので,アクセスの方法によって,シーケンシャル・アクセス,ランダム・アクセスという呼び方をします。シーケンシャル・アクセスとは,ファイルの先頭から順にデータを読み書きする方法です。これに対し,ランダム・アクセスはファイルの任意の位置から読み書きする方法で,ハードディスクやCD-ROMのアクセスに似ています。
今回は,テキスト・ファイルにシーケンシャルにアクセスする方法を見ていきましょう。
ファイルを開くfopen,閉じるfclose
ファイル中のデータを読み書きするには,準備としてファイルをオープン(開くこと)しなければなりません。
リスト1はテキスト・ファイルをオープンし,内容を表示して閉じるだけのプログラムです。fopen,fcloseという二つの関数を使っています(表1)。ファイルを扱うモードは3種類あります(表2)。リスト1の(1)が,テキスト・ファイルtext1.txtをrモード(読み込み専用)でオープンするコードです。
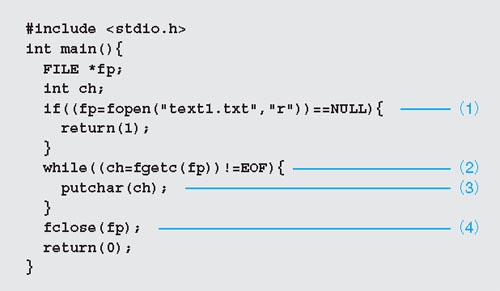 リスト1●テキスト・ファイルを開いて読み込むプログラム
リスト1●テキスト・ファイルを開いて読み込むプログラム
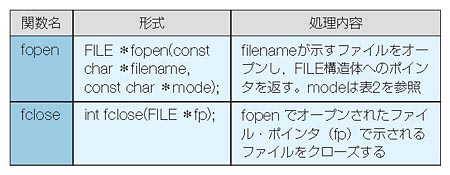 表1●ファイルのオープン/クローズ関数
表1●ファイルのオープン/クローズ関数
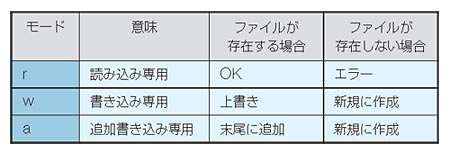 表2●ファイルのオープン・モード。r+,w+,a+のように+を付けると読み書き両用になる
表2●ファイルのオープン・モード。r+,w+,a+のように+を付けると読み書き両用になる
fopen関数はファイルのオープンに成功すると,ファイル・ポインタを返します。ファイル・ポインタとはFILE構造体へのポインタです。FILE構造体へのポインタ(fp)にはそのファイルにアクセスするために必要となる情報への参照がセットされています。ファイルが存在しないなどの理由でファイルのオープンに失敗すると,fopen関数はNULLを返します。
(2)のfgetc関数はファイルから一文字ずつ読み込みを行います。EOF*10-2を返すまで一文字ずつの読み込みを繰り返し,(3)のputchar関数で標準出力(ディスプレイ)に表示します。また,ファイルは使い終わったら閉じなければなりません(クローズするといいます)。(4)でファイル・ポインタ(fp)で示されるファイルをクローズしています。
では今度は一文字単位の出力を行うfputc関数を使って,ファイルの内容をコピーするプログラムを見てみましょう。関数については表3を参照してください。
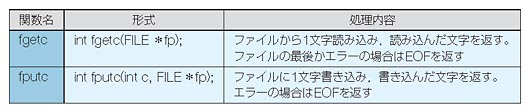 表3●文字単位の入出力を行う関数。fgetc関数と同様に一文字入力を行うgetcはマクロとして実装されている。また,fputc関数と同様に一文字出力を行うputcもマクロとして実装されている
表3●文字単位の入出力を行う関数。fgetc関数と同様に一文字入力を行うgetcはマクロとして実装されている。また,fputc関数と同様に一文字出力を行うputcもマクロとして実装されている
リスト2では,fpi,fpoと入力,出力用のファイル・ポインタを宣言しています。また,ファイル名をscanf関数で受け取れるように(1)でchar型の64バイトの配列を二つ宣言しています。scanf関数で受け取ったファイル名のファイルをオープンできなかったとき,(2)のputcharでは「\a」というビープ音を鳴らすエスケープ・シーケンス*10-3を送り,ビーというビープ音を鳴らし,メッセージを表示してexit関数でプログラムを終了させています*10-4。実行させると図1のように1文字ずつ入力と出力を繰り返し,ファイルの内容を別のファイルにコピーするというわけです。
 リスト2●テキスト・ファイルの内容をコピーするプログラム
リスト2●テキスト・ファイルの内容をコピーするプログラム
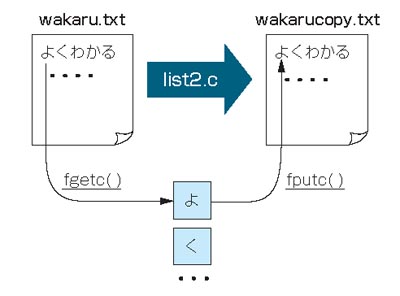 図1●リスト2の実行イメージ。wakaru.txt内の文字をfgetc関数で1文字ずつ読み込み,ftputc関数でwakarucopy.txtに出力している
図1●リスト2の実行イメージ。wakaru.txt内の文字をfgetc関数で1文字ずつ読み込み,ftputc関数でwakarucopy.txtに出力している
コマンドライン引数でファイル名を指定する方法
さて,ここで処理すべきファイル名を与える方法について整理しましょう。
リスト1では,プログラムの中にファイルを直接埋め込みました。いわゆるハード・コーディングですね*10-5。別のファイルを使いたいときはソースコードのレベルで修正しなくてはなりませんので,このような書き方はあまり良い方法ではありません。一方,リスト2ではscanf関数で,標準入力(キーボード)からファイル名を受け取っています。
もう一つ,覚えておいてもらいたい方法があります。コマンドライン引数です。本連載で利用しているBorland C++ Compiler 5.5でコンパイルするときに,図2のようにコマンド名に続けてソース・ファイル名を指定しますね。これがコマンドライン引数です。
 図2●コンパイルするときに指定するのがコマンドライン引数。この場合は「n10_1.c」に相当する
図2●コンパイルするときに指定するのがコマンドライン引数。この場合は「n10_1.c」に相当する
C言語では,入力されたコマンドライン引数をmain関数の引数から取得できます。サンプル・プログラムを見てみましょう。リスト3は,コマンドライン引数で指定したファイルを読み込み,その内容を表示するプログラムです。
 リスト3●コマンドライン引数で指定したファイル名の内容を表示するプログラム
リスト3●コマンドライン引数で指定したファイル名の内容を表示するプログラム
main関数の引数としてargcとargvがありますね(1)。argcがargument count (引数の数)で,argv[]配列には入力された文字列へのポインタが格納されます。コマンド名自体も引数の数にカウントされ,argv[0]はコマンド名を指します。(2)で「if(argc!=2)」としているのはなぜだかわかりますか? ちょっとわかりにくいと思うので,argcとargvの内容を表示させるプログラムを作って確認しましょう。
リスト4をコンパイルして,仮にコマンドライン引数を「-name mysql」として実行してみます。結果は図3のようになるでしょう*10-6。argv[]配列に三つの引数が設定されていることがわかると思います。つまり,リスト3の(2)では,argcが2でないときは,入力すべきファイルが指定されていないか,余計な引数が指定されていると判断しているのです。
#include <stdio.h>
int main(int argc, char* argv[]) {
int i;
printf("引数の数:%d \n", argc);
for(i=0; i<argc; i++) {
printf("argv[%d] = %s \n", i, argv[i]);
}
return(0);
}
リスト4●実行プログラムとコマンドライン引数を配列に格納するプログラム
 図3●コマンドライン引数を「-name mysql」にしてリスト4を実行したところ
図3●コマンドライン引数を「-name mysql」にしてリスト4を実行したところ
リスト3の説明に戻ります。リスト3をコンパイルしてテキスト・ファイルを指定して実行すると,中身がそのまま出力されます。リスト3の(3)のargv[1]にテキスト・ファイルの文字列へのポインタが入っているのでファイルをオープンできるわけですね。(4)のfgets関数は,ファイルから1行ぶんを入力し,(6)のputs関数は標準出力に行単位に出力します。fgetsとputs関数については表4を参照してください。
 表4●行単位の入出力関数
表4●行単位の入出力関数
特に説明が必要なのは(5)のコードでしょう。strlen関数でline配列の文字数を求めて,文字数-1の位置に\0(NULL)を代入しています。何のためにこんな処理が必要になるのでしょう。図4をご覧ください。fgets関数は改行コード(\n)に出合うと,その後ろにNULL (\0)を書き込みます。puts関数はNULLに出合うと,改行コードに変換して出力を終えるので,1行に二つ改行コードが入ってしまうことになります。そこで,NULLまでの文字数をカウントするstrlen関数の戻り値-1の要素(=改行コード)をNULLに換えているのです*10-7。
 図4●リスト3の(5)の行が必要な理由。「Thanks!」という文字列を読み込むとする
図4●リスト3の(5)の行が必要な理由。「Thanks!」という文字列を読み込むとする
標準入力,標準出力,標準エラー出力
これらもファイルである
さて,ファイルというものはオープンして読み書きしたら,必ずクローズしなくてはいけないと説明しましたが,実はオープン/クローズが不要なファイルが三つあります。標準入力,標準出力,標準エラー出力と呼ばれるファイルです。
図5のように標準入力(stdin)はキーボードに,標準出力(stdout)と標準エラー出力(stderr)はディスプレイに設定されています。キーボードやディスプレイがファイルというのは感覚的にしっくりこないかもしれませんね。でも,もともとUNIX系のOS開発のために作られたC言語では,キーボードやディスプレイなどの周辺装置もファイルとして扱うのです。
 図5●標準入力,標準出力,標準エラー出力のイメージ
図5●標準入力,標準出力,標準エラー出力のイメージ
例えばリスト3の(5)(6)の部分を,
fputs(line,stdout);
のように出力先をstdout(標準出力)に変更して実行すると,同じように,コマンドライン引数に指定したファイル内容をディスプレイに表示します*10-8。つまり,標準出力もファイルのように扱うことができるわけです。標準入力,標準出力,標準エラー出力はプログラムの開始時点に自動的に開き,終了時点に勝手に閉じるファイルだと考えればいいでしょう。
図5にあるバッファについて少し触れておきましょう。C言語では標準入出力だけではなく,すべてのファイルを読み書きする場合に,バッファを使ったストリーム入出力を行います。ストリーム入出力では,関数が直接ファイルにアクセスするのではなく,間にバッファをかませた入出力を行います。プログラムはバッファから読み込み,バッファに書き込みます。バッファが空になったら,OSが自動的にファイルから読み込みます。バッファがいっぱいになったら,バッファからファイルに書き込みが行われます。この仕組みによって,C言語では効率的なファイルのアクセスが実現できるのです。
書式を付ける入出力関数もある
一文字入出力,一行入出力の後は,書式付きの入出力を行う関数を紹介しましょう。標準入出力へ書式付きの入出力を行う関数がscanf関数とprintf関数ですから,先頭にfを付ければファイルへの書式付き入出力を行う関数になることが想像できるでしょうね。実際,その通りです(表5)。
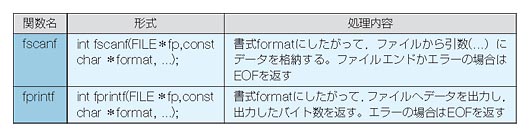 表5●書式付きの入出力関数
表5●書式付きの入出力関数
fscanfとfprintf関数を使ったサンプルを見てみましょう。リスト5は,テキスト・ファイルを行単位に読み込み,行番号を付けて別のファイルに出力するプログラムです。fprintf関数で出力ファイルに書式付きで保存しています(3)。ファイル名の入力にもscanf関数ではなく,fscanf関数でstdin(標準入力:キーボード)から読み込むようにしてみました(1)。また,ファイル・オープン失敗時のエラー・メッセージもfprintf関数の引数にstderr(標準エラー出力)を指定してディスプレイに表示させています(2)。
 リスト5●テキスト・ファイルに行番号を付けて出力するプログラム
リスト5●テキスト・ファイルに行番号を付けて出力するプログラム
ファイルを連結させてヘッダーを付けるプログラムを作ろう
ここまでの説明で,テキスト・ファイルのシーケンシャル・アクセスについて概略を理解できたでしょうか。単純なサンプルばかりでは面白くないので,最後にファイル操作のテクニックを使って,「ちょっとしたツール」を作ってみることにしましょう。
といっても,ツールにはいろいろなニーズがあると思うので,ここでは筆者がこの連載記事を執筆するにあたって役立ちそうなツールを紹介したいと思います。筆者は,本連載を書くときに,まずサンプル・プログラムをダッーといくつか作成し,その中から掲載するプログラムを選んで一つのテキスト・ファイルに連結して編集部に送付しています。一つのファイルにしたほうが全体の分量などを見積もるときに便利だからです*10-9。具体的にいうと,図6のようにテキスト・エディタで編集しています。
 図6●筆者がサンプル・プログラムを作成したファイル
図6●筆者がサンプル・プログラムを作成したファイル
このときよく間違えるのがリスト1,リスト2とヘッダーを記入することです。ついうっかりして,リスト2を二つ作ったりしてしまうわけです。それから,「面倒だな」と感じるのが,(1),(2),(3)…と本文で説明したい部分に番号を付ける作業です。最初から説明する場所をきちんと決めて,そのまま原稿を書き進めていければよいのでしょうが,「やっぱりここも説明しよう」などと思い直していると,説明する部分が執筆途中で増減します。すると,そのたびに番号を振りなおさなければなりません。本当は,「どう説明すれば,わかりやすいだろう。こんな書き方ではどうだろう」と考えることにエネルギーを向けたいのですが…。
そこで,リスト6のプログラムを作成してみました。複数の入力ファイルを読み込み,出力ファイルに書式付きで書き出していくプログラムです。最大10個のソース・ファイルを一つのテキスト・ファイルに連結して出力できるように,(2)のdefineで「FILENUM 10」とマクロ定義しています。ファイル・ポインタも入力ファイル名を格納する配列も10個作成します(3)(4)。(5)のscanf関数でファイル名をキーボードから読み込み配列に格納します。「q」が入力されると,入力ファイル名の読み込みを終えます。(6)で「tolower(fnamei[i][0])」と英大文字を小文字に変換するtolower関数でfnamei[i]配列の最初の文字を変換している理由は,Qと大文字で入力されても,breakできるようにするためです*10-10。入力されたファイル名のファイルを(7)ですぐ開いています。もし,ファイルがオープンできなかったときは,ループ・カウンタであるiをデクリメントして,continue文で再度,ファイル名の入力を受け付けます。一番目のファイル名で,いきなりqと入力された場合に出力ファイル名の入力に進まないように,(8)でiが0のときはプログラムを終了させています。
 リスト6●サンプル・プログラムを連結させてヘッダーを付けるプログラム
リスト6●サンプル・プログラムを連結させてヘッダーを付けるプログラム
(9)以降で入力ファイルを順に行単位に読み込み,ファイル単位で連番を付けて出力していきます。各ファイルの先頭には,(10)のheader_out関数でヘッダーを出力します。header_out関数には,出力ファイルのファイル・ポインタと何番目のファイルを処理しているかを示す番号とその番号に対応するファイル名を渡しています。
このプログラムを実行してファイル名を入力し,作成されたファイルの中身が図7です。各サンプル・プログラムにヘッダーと行番号が付いていますね。
 図7●リスト6を実行してできたファイルの例
図7●リスト6を実行してできたファイルの例
多くの人に役立つ汎用的なツールを作るには,それなりのエネルギーが必要ですが,自分だけの一時的な都合に合わせただけのツールなら意外に簡単に作れます。後はコツコツとバージョンアップを重ねていけばいいのです。例えばHTMLファイルとしてWebにアップできるようにするために改行コードは
タグに変換するとか,半角スペースやタブは に変換するとか…そのようなことを繰り返していると,いつのまにか汎用的なツールに進化していることがあるものです。今回はたまたま筆者にしか役立たないサンプルになりましたが,とにかく何か作り始めることが大事です。誰のためなんて考えなくて結構。自分だけのためでいいのです。そうやって手を動かしていれば,少しずつアイデアが湧いてきます。
今回は簡単な内容だったので,サラッと読めて物足りなかったかもしれません。次回はランダム・アクセスとバイナリ・ファイルの扱いに話を進めていきます。ぜひ続けてお読みください。
第11回 ランダム・アクセスと バイナリ・ファイルの扱いを学ぶ
前回から2回にわたり,C言語によるファイル処理を説明しています。前回は,テキスト・ファイルにシーケンシャルにアクセスして,先頭から順に読み書きする方法を解説しました。バッファを使ったストリーム入出力で効率良くファイルにアクセスできることや,キーボードやディスプレイなどの周辺機器も標準入出力としてファイルのように扱えることを説明しましたね。2回目となる今回は,ランダム・アクセスとバイナリ・ファイルの操作について説明します。まずは,ランダム・アクセスから解説を始めましょう。
ランダム・アクセスはファイルの任意の位置からデータを読み書きする方法で,ハードディスクやCD-ROMのアクセスに似ています。
一つのデータの長さが決まっている固定長のファイルなら,ファイルの中の関連するデータの固まり(レコード)に,どこの位置からでもアクセスすることができて便利です。シーケンシャルにファイルを読み込む場合,ファイルをオープンした時点でのファイル・アクセスの基点はファイルの先頭です。データを読み込んでいくと現在位置もそれに合わせて変わっていきます。ですから,一文字入力を行うfgetc関数でファイルを読み込んだときや一行入力を行うfgets関数で読み込んだときも,特別な操作なしに順々にデータを読み込んでいくことができたわけです。
これに対し,任意の位置から読み書きを行うには,ファイル内の現在位置を移動させる必要があります。この現在位置のことを,一般的にファイル・ポインタやファイル・ポジションと呼びます。ただ,ファイル・ポインタというと,fopen関数が返すFILE構造体へのポインタと紛らわしいので,ここでは「ファイル位置指示子」という名前で呼ぶことにしましょう。ハードディスクのどこにそのファイルが存在するかを指示するような感じを持たれるかもしれませんが,ファイルのどこがカレントな位置(現在位置)なのかを示すのがファイル位置指示子であると理解してください。
アクセス・カウンタを作ってみよう
まずはサンプルとして,Webサイトの訪問者数を記録するアクセス・カウンタを作ってみましょう。count.txtというテキスト・ファイルに訪問数を記録するプログラムです(リスト1)。特に問題はなさそうですね。count.txtには,図1のように0を六つ並べて「000000」と書き込んでおきます。メモ帳などのテキスト・エディタを使うといいでしょう。
 リスト1●アクセス・カウンタのプログラム
リスト1●アクセス・カウンタのプログラム
 図1●テキスト・ファイルcount.txtに,000000と書き込んでおく。最後に改行しないこと
図1●テキスト・ファイルcount.txtに,000000と書き込んでおく。最後に改行しないこと
リスト1のプログラムをコンパイルして1回だけ実行すると,確かに「000001」とカウントアップされます。しかしその後,何回このプログラムを実行しても,「000001」のままです(図2)。まったくカウントアップしません。テキスト・エディタであらためてcount.txtを開いて見ると,000000の後に000001と書き込まれているのがわかります(図3)。なぜ,こうなってしまうのでしょう?
 図2●リスト1を何回実行しても,「000001」としかならない
図2●リスト1を何回実行しても,「000001」としかならない
 図3●count.txt内が想定どおりになっていない
図3●count.txt内が想定どおりになっていない
ソースコードを追って考えていきましょう。リスト1をよく見てください。まず(1)で,ファイルcount.txtを読み書き両用モード(r+)でファイルを開いています。読み書き両用のモードは,表1のように3種類あります。(2)では,count.txtから現在の値を読み出しています。最初は000000を読み込んでlong型の変数iに代入していますね。それを(3)のi++で1加算して,(4)のfprintf関数で6桁の000001とファイルに書き込んでいるはずです。なのに,なぜ000000が000001と上書きされずに「00000000001」となったのでしょう?
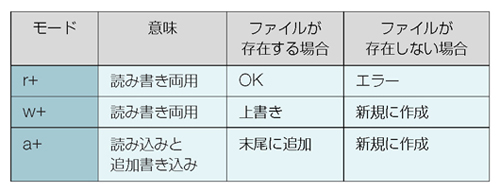 表1●読み書き両用の場合のファイルのオープン・モード
表1●読み書き両用の場合のファイルのオープン・モード
その理由は,前述のファイル位置指示子にあります。最初,ファイルを開いたときのファイル位置指示子は,「000000」の先頭にあります。しかし,(2)のfscanf関数を実行すると,ファイル位置指示子は図4のように移動してしまうのです。すると(4)のfprintf関数は,ファイル位置指示子の指す位置から6桁分を書き込み,000000の後に000001と追記することになります。その結果,次にcount.txtファイルをオープンしても,最初の6桁である「000000」の部分しか読み込まないので,いつまでたってもカウントアップしないわけです。
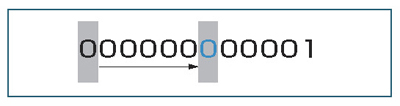 図4●fopen関数を実行するとファイル位置指示子は移動してしまう
図4●fopen関数を実行するとファイル位置指示子は移動してしまう
ftell関数で現在位置を知りrewind関数で元に戻る
ファイル位置指示子がどこを指しているのかという情報は,ftell関数を使うと知ることができます。ftellは,引数としてファイル・ポインタ(FILE構造体へのポインタ)を受け取り,現在位置をlong型で返す関数です。例えばリスト2ではftell関数を使って,読み込み前後/書き込み前後の現在位置を表示させています(図5)。
 リスト2●ftell関数を使ったプログラム
リスト2●ftell関数を使ったプログラム
 図5●リスト2を実行したところ
図5●リスト2を実行したところ
ファイル・ポインタを操作する関数は,ftell関数のほかにrewindとfseek(後述)があります(表2)。まず,rewind関数から見てみましょう。リスト2では,ファイル・オープン直後(読み込み前)の現在位置は0,fscanf関数で読み込み後の値は6です。(1)のrewind関数は,ファイル位置指示子をファイルの先頭に戻します。要するにリワインド:巻き戻しですね。つまり(2)で,ファイル位置指示子の現在位置は0になります。
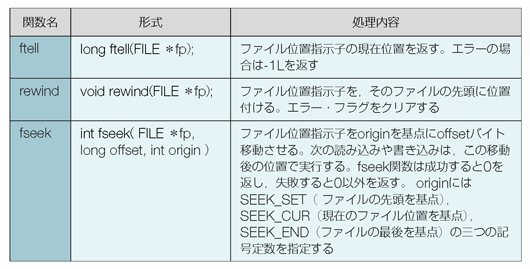 表2●ファイル位置指示子を操作する三つの関数
表2●ファイル位置指示子を操作する三つの関数
実際にリスト2のプログラムをコンパイルして実行してみてください。プログラムを繰り返し実行すると,カウンタの数が一つずつアップしていくのがわかると思います。ファイル位置指示子を移動させることで,カウント・アップした値を上書きすることができたわけです*11-1。
ランダム・アクセスにはfseek関数を使う
ここで「冒頭で述べたランダム・アクセスの話題はどうなったんだ?」と思った方は鋭いですね。そう。よく考えてみると,実はリスト2のプログラムはランダム・アクセスの説明になっていません。というのも,rewind関数はファイル位置指示子をファイルの先頭に戻すだけで,シーケンシャル・アクセスを2回繰り替えしているにすぎないからです。fscanf関数で値を読み込んだあと,ファイルをクローズして,再度オープンしてカウント・アップした値を書き込んでも同様の結果を得ることができます。
そこで,真のランダム・アクセスを実現するのに使うのが,表2で紹介した,任意の位置にファイル位置指示子を移動させるfseek関数です。seekという単語からは何かを探してくれそうな感じがしますね。実際には表2にあるように,ファイル・ポインタfpで示されるファイルのorigin (SEEK_SET,SEEK_CUR,SEEK_END)を基点に,offsetバイトぶん,ファイル位置指示子を移動させます。自分が読み書きしたいレコード(データのまとまり)が,ファイルの先頭から何バイト目にあるかがわかれば,ランダムにアクセスできるというわけです。
少し長いですが,リスト3のプログラムを見て,fseek関数の動作を確認してみましょう。リスト3は,複数のユーザーIDとパスワードを何セットか別々のファイルに記録するプログラムです。ちなみに,このプログラムは次のようなニーズで作成しています。
 リスト3●ユーザーIDとパスワードをセットにして保存するプログラム
リスト3●ユーザーIDとパスワードをセットにして保存するプログラム
●ユーザーIDは20バイト,パスワードも20バイトを最大長として,40バイトのレコードとして扱う
●ファイルの先頭から5バイトは,登録済みのレコード数の記録に使用する
●5バイト目以降は,40バイトのレコード(ユーザーIDとパスワード)が登録順に並ぶ
●登録時には,レコードの何番目のレコードかを示すNOを表示する
●表示/修正時はNOでレコードを呼び出す
リスト3のプログラムを実行して,図6のように2件のレコードを登録してみてください。このとき,テキスト・ファイルには,図7のようにユーザーIDとパスワードのセットが記録されるはずです。
 図6●リスト3を実行して2件のデータを登録したところ
図6●リスト3を実行して2件のデータを登録したところ
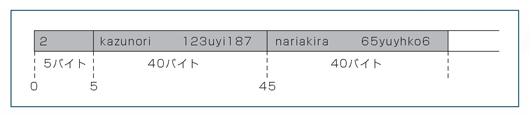 図7●図6の段階では,二つのレコードが並んでファイルに記録される
図7●図6の段階では,二つのレコードが並んでファイルに記録される
リスト3のソースコードを見ていきましょう。まず最初に(1)で,defineプリプロセッサ命令を使い,「REC_SIZE 40L」とレコードのサイズをユーザーID(20バイト)+パスワード(20バイト)の合計40バイトにマクロ定義しています。Lはlong型を表します*11-2。
(2)以降でプロトタイプ宣言している関数が四つあります。fileopen関数は,ファイル名の入力を受け付けてファイルをオープンします。ファイルが存在した場合は先頭のレコード数を読み込み,件数として表示します。writerecは既存レコードの末尾にレコードを書き込み,カウント・アップしたレコード件数をファイルの先頭に書き込む関数です。showrec関数は指定されたレコードNOのレコードを読み込んで表示します。updrec関数はshowrec関数の処理プラス,変更する値を入力させて上書きする機能を持っています。
いずれの関数にも共通しているのは,
REC_SIZE*(no-1)+5L
という式でfseek関数のoffsetに指定する値を求めている点です。つまり,ここがランダム・アクセスのポイントとなる処理です。例えば2番目のレコード位置を求める場合は,「40×(2-1)+5」となるので45(45バイト目)となり,直接2番目のレコードにアクセスできるようになるわけです。
ファイル・ポインタfp,no,offsetは各関数で使用するので,グローバル変数として宣言します(3)。
fileopen関数の中を見てみましょう。(4)のfopen関数でr+モード(読み書き両用モード)で入力されたファイルをオープンしています。もしオープンできなかったら*10-3,w+で再度オープンしています。表1にあるように,w+モードではファイルが存在しないと新規にファイルを作成します。ファイルが存在した場合は(5)でグローバル変数noにレコード件数を代入し,現在の件数を表示しています(6)。
続くwriterec関数では,noをインクリメントして(7),ファイル位置指示子を移動させてレコードを書き込んでいます。レコードを書き込んだ後は,(8)のrewind関数でファイルの先頭に戻り,インクリメントされたレコード件数を書き込みます。rewind関数は「fseek(fp, 0L, SEEK_SET)」と同等と考えることができます。
showrec関数は特に説明することはありませんが,(9)は入力されたNOがレコード件数より大きいときや1より小さいときのエラー処理です。
updrec関数では,(10)で目的のレコードに移動して表示した後で,再度ファイル位置指示子をoffsetに移動させています。上書きするために(11)の処理が必要なのですね。
さて,全体のアルゴリズムについて,なんとなくでも理解できたでしょうか。実行させてみると,ファイルにランダムにアクセスする様子が実感できると思います。
もしよくわからない場合は,もう一度最初から1行ずつコードを読んで実行結果と見比べてください。ランダム・アクセスを覚えると,小回りの効くファイル処理を作成できるようになります。構造体をレコードとして保存できるようにしたり,入力された文字列と比較/検索を行う処理を作れば,データベースを使わなくても,ちょっとしたファイル処理を作成できます。ぜひ,トライしてみてください。
C言語はバイナリ・ファイルを“そのまま”開ける
さて,ここからは今回二つ目のテーマである,バイナリ・ファイルについて話を進めていきましょう。
バイナリ・ファイルをインターネットで検索すると
画像,動画,音声ファイル,実行可能形式のプログラム・ファイルなどを指す。専用のアプリケーション・ソフトで扱うことを前提としており,テキスト・エディタでは開けない。文字コードの範囲などを考慮せずに作成されたファイルである。
といった説明を目にすることが多いと思います。バイナリ・ファイルは,テキスト・ファイルの対義語として使われており,バイナリ,つまり2進数が並んだファイルという風に説明されているわけです。
確かにその通りなのですが,筆者にはやや違和感があります。コンピュータではあらゆるデータを2進数のイメージで扱いますから,テキスト・ファイルだって実態は2進数が並んだファイルです。実際にAとかBとか,文字がファイルの中に入っているわけではありません。テキスト・ファイルも中身は当然2進数,つまりバイナリ・データの並びなのです。でもテキスト・ファイルに含まれるバイナリの並びはASCII(アスキー)コードを始めとする文字コードが中心で,改行やタブなどの一部の制御コードしか含んでいません。そのため文字として解釈できるのです。解釈といっても独自のプログラムは不要で,OSなどが勝手に解釈し,文字列として読むことができるのがテキスト・ファイルです。
一方,(OSの標準機能ではなく)個別のプログラムで解釈しなくてならないのがバイナリ・ファイルということになります。Microsoft Wordで作った文書ファイルを正確に再現するには,Wordを使わなくてはならないのと同じ理屈です。
では,C言語のプログラムはどうでしょう。実はC言語では,バイナリ・ファイルを「そのまま」読み書きできます。表3のようにバイナリ・モードを指定してファイルを開くと,バイナリの並びをそのまま読んでくれるのです。テキスト・ファイルも,もちろんバイナリ・モードで読み書きすることができます。
 表3●バイナリ・ファイルのオープン・モード
表3●バイナリ・ファイルのオープン・モード
ダンプ・プログラムを作って“そのまま”開くを実感する
“そのまま読む”ということはどういうことかを実感するために,ファイルの内容を16進数でダンプするプログラムを作ってみましょう。
リスト4は,コマンドライン引数で指定されたファイルの内容を16進数で表示し,ASCIIコードで評価して,表示可能な文字は文字として表示するプログラムです。
 リスト4●ファイルの内容を16進数でダンプするCのプログラム
リスト4●ファイルの内容を16進数でダンプするCのプログラム
(1)でfopen関数の引数にコマンドライン引数として渡されたファイル名と,オープンモードrbを指定してファイルを開いています。(2)のtitle_outはダンプするファイル名を表示する関数です。(3)のforループの中で1文字ずつ読み込み,標準出力に出力していきます。16ずつインクリメントしているのは,1行に16文字分表示するからです。16*MAXを上限としてループを繰り返します*11-4。(4)で変数posの値を表示してファイル内の位置を示しています*11-5。
(5)以降が一行分の処理です。(6)から(7)までの処理はファイルの終端に来たときの,表示の桁合わせのための処理で,重要なのは(8)と(9)です。(9)は読み込んだデータをそのまま16進数で表示します。(8)はそのデータがASCIIコードで表示可能な文字かどうかを判断し*11-6,表示可能であればbuff配列にそのまま代入して,そうでない制御文字などのときは「.」を代入します。これがASCIIコードによる解釈ですね。(10)で文字列の終端を示すNULLをbuff配列に入れ,(11)で表示しています。
このプログラムを使って,リスト1のプログラム(テキスト・ファイル)を表示させたのが図8です。これを見れば,ASCIIコードなどの文字コードで解釈するという意味が理解できると思います。「でも,バイナリ・モードを“そのまま”読むというのがよくわからない…」――確かにそうかもしれませんね。
 図8●リスト4のプログラムでリスト1のファイルを表示させたところ
図8●リスト4のプログラムでリスト1のファイルを表示させたところ
では,もう一度図8を見てください。左側の文字の羅列の中に,0D,0Aというコードの並びが何度も出現していますね。これは改行を表すコードです。Windowsでは,0D*11-7と0A*11-8の組み合わせが改行コードになります。実はこの改行コードがコンピュータの世界を少しややこしくしています。というのはOSの種類によって,改行コードが異なるのです。Windowsでは0Dと0Aの組み合わせですが,UNIXでは0Aだけで改行を表します。また,Macintoshでは0Dが改行コードです。UNIX系OSの開発用に作られたC言語では,実行するOSに関係なく0Aが改行コードです。
バイナリ・モードがファイルをそのまま読むということを理解するために,リスト4のfopen関数のモードを,
if ((fp = fopen(argv[1], “r”))==NULL) {
のように,rbからrに変更して,もう一度リスト1のプログラムをダンプしてみましょう。すると,0D,0Aの並びが0A一文字になるのがわかると思います(図9)。テキスト・モードでオープンすると,OSの改行コードとC言語の改行コードの変換が自動的に行われるのです。それに対して,「そのまま」何もしないで読み書きする方法がバイナリ・モードなのです。
 図9●fopen関数のモードを「r」に変更してリスト1のファイルを表示させたところ
図9●fopen関数のモードを「r」に変更してリスト1のファイルを表示させたところ
バイナリ・ファイルに書き込む方法
次に,Windows付属のアプリケーション「ペイント」で描いたビットマップ(bmp)ファイルを,リスト4のプログラムで表示させてみましょう。
図10は,白い背景に三色の長方形を描いたビットマップ・ファイルをダンプ表示させたものです。40が0x20~7Eの範囲内の値なので@に変換されていますが,この文字の羅列を見ても,何のことだかさっぱりわかりませんね。
 図10●ビットマップ・ファイルをリスト4のプログラムで表示させたところ
図10●ビットマップ・ファイルをリスト4のプログラムで表示させたところ
ビットマップ・ファイルはバイナリ・ファイルの代表的なファイルで,どのような形式でデータが表現されているかを知っているプログラムでないと忠実に表示したり,加工したりすることはできません。bmp形式を扱うことができる画像編集ソフトはたくさんありますが,それらのソフトウエアはみなbmp形式というフォーマットを理解しているわけです。
bmp形式を理解すればC言語でも,ちゃんとビット・マップ・ファイルを加工するプログラムは作れます。しかし,それを説明するとなると,この連載とは別に数ページの解説が必要なので,ちょっと乱暴ですが,あてずっぽうでビットマップ・ファイルを加工してみるプログラムを作ってみました。
光の三原色RGBで,一色の値の範囲が0~255(0x00~0xFF)とすると,3色ともFFにすると白になりますね。逆に全部0にすると黒です。そこで,16進数のFFをA2に変更する処理がリスト5の(1)の部分です*11-9。このプログラムを,変更前のビットマップ・ファイル名,変更後のビットマップ・ファイル名と二つの引数を指定して実行すると,変更後のファイルは,図11の右側のようにくすんだ色になります。画像処理ソフトがやっていることがなんとなく,理解できたでしょうか?
 リスト5●あてずっぽうでビットマップ・ファイルを加工するプログラム
リスト5●あてずっぽうでビットマップ・ファイルを加工するプログラム
 図11●リスト5を実行したところ。左が加工前,右が加工後
図11●リスト5を実行したところ。左が加工前,右が加工後
バイナリ・ファイルというと何か特殊なファイルを想像しがちですが,結局は2進数の0と1のイメージが並んでいるだけです。バイナリの並びをどのように評価すべきかを指定するファイル・フォーマットがわかれば,バイナリ・ファイルをC言語で操作することは難しくありません。
さて,いよいよ次回で最終回です。本連載でC言語の勉強をしてくれた読者には,次にデータベースとオブジェクト指向の勉強してほしいと筆者は考えています。ですから次回は,ごく簡単なオブジェクト指向入門をお届けしたいと思います。どうぞ,お楽しみに!
第12回 構造体に手足を付ければ,それがクラスだ
皆さんはとっくにお気付きかもしれませんが,本連載で使用してきたBorland C++ CompilerはC言語のコンパイラではなく,「C++言語」のコンパイラです。
C++言語はC言語にオブジェクト指向的な拡張を施したプログラミング言語で,Bjarne Stroustrup氏によって仕様が作られました*12-1。C++言語はC言語の上位互換なので,C言語の言語仕様で記述されたプログラムでもコンパイルできたわけです。
筆者は,C言語を理解された方は,次にオブジェクト指向の概念を勉強してほしいと思っています。今やオブジェクト指向は必須の知識ですし,システム設計にもデータベースにもオブジェクト指向の考え方は広まりつつあるからです。
そこで最終回の一回限りですが,オブジェクト指向の概念や機能をC言語に「のっけた」C++言語で,オブジェクト指向プログラミングの世界をのぞいてみましょう。
オブジェクトはプロパティとメソッドを持つ
オブジェクト指向は,現実世界に実在するモノをオブジェクトとしてモデル化し,プログラムに取り込もうとするアプローチです。C言語などの手続き型言語ではデータと手続きは別々に存在し,プログラムで指定した順に手続きがデータを処理していました。一方,オブジェクト指向では,オブジェクトがデータと手続きを持ちます。オブジェクト指向の用語では,このデータのことをプロパティ(属性)またはメンバー変数と呼びます。そして,手続き(振る舞い)のことをメソッドまたはメンバー関数と呼びます。
漠然とした話になってしまいましたね。目覚まし時計で考えてみましょう(図1)。目覚まし時計には「現在の時刻」や「ベルを鳴らす時刻」というデータがあります。これが目覚まし時計のプロパティです。目覚まし時計のメソッドは,「時を刻む」こと,「目覚まし時刻を合わせる」こと,「現在の時刻を合わせる」ことです。もちろんほかにも製造メーカー,製造年,素材などのプロパティや,針を回すなどのメソッドがあります。しかし,モデル化しオブジェクトとしてプログラムに取り込むときは,そのプログラムで扱う必要があるプロパティやメソッドだけに注目して,関係のないものは無視します。現実にあるものをすべて写し取ろうとしゃくし定規に考える必要はありません。
 図1●「目覚まし時計」というオブジェクトを考えてみよう
図1●「目覚まし時計」というオブジェクトを考えてみよう
また,オブジェクトに対し送る指示や設定のことをメッセージと呼びます。例えば,目覚まし時計オブジェクトに「6時45分にベルを鳴らせ」というメッセージを送ることを,メッセージ・パッシングと呼びます。
クラスをインスタンス化して実体=オブジェクトを作る
ここまでで,目覚まし時計のプロパティとメソッドを考えてみました。これは,見方を変えると目覚まし時計というオブジェクトの(概念的な)基本設計に相当します。この基本設計(ひな型)のことを,オブジェクト指向では「クラス」と呼びます。そして,クラスからメモリー上に実体(インスタンス=オブジェクト)を作る(もちろんコード上で)ことを“インスタンスの生成”と呼びます。
インスタンスの生成などというと難しそうですが,C言語の構造体が実は型宣言であり,構造体型の変数をメモリー上に作成して利用するのと考え方は同じです(図2)。実際のプログラムでは,一つのクラスから複数のオブジェクトを生成して処理を行います。誤解を恐れずに言うならば,「クラスからインスタンスを生成する」――最低限これだけできれば,オブジェクト指向プログラミングと言えるわけです。
 図2●基本設計であるクラスから,オブジェクトを生成する
図2●基本設計であるクラスから,オブジェクトを生成する
オブジェクト指向の三本柱はカプセル化,継承,多態性
オブジェクト指向プログラミングの目的は,大規模なプログラムの複雑さを軽減し,効率的なプログラミングを実現することです。そのための三つの柱が,カプセル化,継承,多態性です。
まず,「カプセル化(情報隠ぺい)」から解説しましょう。カプセル化とは外部に公開する必要のない(もしくは,公開したくない)プロパティやメソッドをオブジェクトの外部から参照できないようにすることです。不用意な値の変更を防止して安全性を高めようというわけです。
例えば,目覚まし時計がベルを鳴らす時間を,プログラムのどこからでも書き換えることができたらどうでしょう。予期せぬ時刻に目覚ましが鳴ったら困りますよね。そこで,こういうときは,“目覚ましの時刻”を隠ぺいして,“目覚ましの時間をセットするメソッド”を公開します。時刻を変更したいときは,時刻を直接変更するのではなく,メソッドを使って変更します。そうすれば,おかしな時間に鳴るようなことがないよう,メソッドの中で不正な値を除外でき,安全性を高められます。目覚まし時計オブジェクトを利用するときは「目覚まし時間を○○時に設定してくれ」というメッセージを送ればいいのです。
オブジェクト指向プログラミングの2番目の柱が「継承」です。継承とは他のクラスのプロパティやメソッドを引き継いで新しいクラスを定義することです。継承を使うと,既存のクラスから新しいクラスを作成し,新たに機能を追加したり変更したりできます。継承される(継承元となる)クラスを基底クラス,親クラス,スーパークラスなどといい,新たに作成するクラスを派生クラス,子クラス,サブクラスなどといいます。
親がいて子を作るのが継承ですが,設計段階では逆の順序で考えます。例えば,犬クラスを作りたいとしましょう。犬クラスを作る必要があるのだから,きっと猫クラスや牛クラスも必要だろうと推測できます。実際,犬,猫,牛には共通点が多くありますね。鳴きますし,4本足で歩きます。そういった共通点に注目し,親クラスを導き出します。つまり,親から子ではなく,子から親を考えたわけです。この作業を汎化と呼びます。
図3の場合,汎化を行うと「動物」という実際には存在しない抽象的な親クラスがあって,そのプロパティや属性を引き継いだ犬クラス,猫クラス,牛クラスが子クラスとして定義されます。難しく言うと設計段階での汎化が,プログラミング段階での継承になるのです。この場合,犬は動物であり,猫も動物ですから,クラス間の関係は「is_a関係(bはaである)」もしくは「a_kind_of関係」にあるということになります。継承を使うと,基本機能に差分機能だけをプログラミングすれば拡張できるので,プログラミングの開発効率を上げることができます。
 図3●子クラスから親クラスを考えることを「汎化」と呼ぶ
図3●子クラスから親クラスを考えることを「汎化」と呼ぶ
さて,オブジェクト指向プログラミング三つ目の柱が「多態性(ポリモーフィズム)」です。多態性とは,同じ名称で指示される操作が,様々な対応や様相を実現するという特性です。引数の数や型が異なる同一名のメソッドを複数作る「オーバーロード(多重定義)」と,親クラスで定義されているメソッドを,サブクラスにおいて同じ名前で定義し直す「オーバーライド(再定義)」で実現できます。
少し乱暴な言い方をすると,犬に「鳴け」というメッセージを送ったら「ワン」と鳴くのは当たり前ですが[*12-2](#jump12-2],仮に小屋の中に犬か猫か牛か,どの動物がいるのかわからない状況で「鳴け」というメッセージを送ったら,その動物が猫ならば「ニャン」と鳴き,牛ならば「モー」と鳴くのが多態性です(これはあくまで「たとえ話」と割り切ってください)。
手続き型言語だと,コンパイル時に呼び出す関数が決まってしまいますよね。しかし,多態性を利用すると実行時に動的に処理するオブジェクトを決めることができるので,柔軟なプログラミングが可能になるのです。
説明ばかりで嫌になってきました。ここからはサンプル・プログラムで考えていきましょう。複雑そうに思える概念もコードに落とし込めば理解が早くなりますから。
最初に構造体を使って考える
では,コンビニエンス・ストアの店長になったつもりで,図4を見てください。プリンを仕入れて棚に並べて売るとしましょう。店長であるあなたは,何日に,いくつ仕入れたプリンが,いくつ売れて,売上金額はいくらになったのかが気になるでしょう*3。加えて,プリンには賞味期限がありますから,「あと何日で期限だけど,残っているのはいくつだ」ということも考えなくてはなりません。では,これをプログラムで表現してみます。
 図4●プリンという商品で管理したい情報とは?
図4●プリンという商品で管理したい情報とは?
プリンの商品別,入荷日別の管理を,これまで勉強したC言語で実現しようとしたら,本連載の第8回で説明した構造体を使うのが最も簡単です。例えば図5のような構造体を作り,個々の商品,入荷日別に構造体変数を作成して管理します。この構造体変数を外部の関数で処理し,販売数や入荷数を増やしたり,現在の情報を表示させたりするわけです。
 図5●プリン構造体のイメージ
図5●プリン構造体のイメージ
リスト1のコードを見てみましょう。main関数でpudding構造体の実体である変数purinを作成し(1),初期値を与えています。次にselled関数にpurinのアドレスを渡しています(2)。selledはポインタで引数を受け取る関数です(4)。構造体のメンバーの値をselled関数で変更できるようにするためですね。構造体をポインタで扱うと「->(アロー演算子)」で構造体のメンバーを参照できます(5)。覚えていますか?
 リスト1●構造体を使ったプリンの管理プログラム
リスト1●構造体を使ったプリンの管理プログラム
(3)で呼び出すdisp関数は各メンバーの値を表示します(6)。販売金額はgetsale関数で計算させています(7)。このプログラムを実行させると図6のようになります*4。この程度なら,本連載を読んできた皆さんなら,すぐ理解できると思います。
 図6●リスト1を実行したところ
図6●リスト1を実行したところ
構造体に手足を付けるとクラスになる
では,このプログラムをオブジェクト指向で作り直してみましょう。リスト2が,リスト1をC++言語を使ってオブジェクト指向プログラミング技術で書き直したものです。構造体がクラスになっています。name,price,inamountはC++言語の用語でいうとメンバー変数(プロパティ)ですから,この構造体にメンバー関数(メソッド)を加えてやったものがクラスだと考えることができます。
 リスト2●リスト1をC++言語でオブジェクト指向化したプログラム
リスト2●リスト1をC++言語でオブジェクト指向化したプログラム
リスト2のコードを読んでみましょう。といっても,いきなりC++言語のプログラムを読むのですから,わからないことばかりだと思います。細かい違いには目をつぶって大筋をつかめばいいので,がんばってついてきてください。
まず(1)のinclude文で「.h」がない点,また(2)のusing namespaceのnamespace(名前空間)については,ここでは説明しません。そういうものなのだ,おまじないなのだと思ってください。
C++では,クラスの定義は(3)のように「class クラス名」ではじめます。構造体の宣言と似ていますね。次の「public」は,アクセス制限の指定です。publicなメンバー(変数,関数とも)はクラスの外から参照/更新ができる公開されたメンバーです。構造体のメンバーはすべて公開されているので,クラスのすべてのメンバーをpublicで宣言するとアクセス制限については構造体と同じになります。
クラスにはメンバー変数に加えてメンバー関数を定義します。(4)以降です。といっても,クラス定義のブロック内に記述するのはプロトタイプだけで,実装は別ブロックに記述します*12-5。メンバー関数の前には所属するクラスを指定するために「Pudding::selled」のように「クラス名::」を指定します*12-6。
メンバー関数には二つの特殊な関数があります。Pudding関数と~Pudding関数です。C++言語の場合,クラス名と同名な関数をコンストラクタと呼び,先頭にチルダ(~)を付けた関数がデストラクタになります。
コンストラクタは,クラスから実体(オブジェクト)が生成されるときに,自動的に実行されるメンバー関数です。メンバー変数の初期化を行う場合などに用います。例えば(5)のコンストラクタでは,引数を受け取ってメンバー変数を初期化しています。outamount(販売数)は当初「0」に決まっているので,コンストラクタの中で0を代入しています。
デストラクタはコンストラクタの逆です。オブジェクトが破棄されるときに自動実行される処理です。使用していたメモリー領域の解放やファイルのクローズなどを行います。リスト2では,coutで文字列を出力しています(6)*12-7。
(10)のmain関数では,オブジェクトpurinを生成し,(7)のselledメンバー関数で売上数をインクリメント(増やす)して,(8)のdispメンバー関数を呼び出しています。dispメンバー関数では(9)のgetsale関数を呼び出し,販売金額を求めた後,各メンバー変数の値を表示しています。
では,リスト2のプログラムを実行してみましょう。注意してほしいのは,プログラム・ファイルの拡張子です。.cではなく,.cppにしなくてはなりません*8。実行して,図7のようになることが確認できましたか?
 図7●リスト2を実行したところ
図7●リスト2を実行したところ
記述方法の違いにとまどわれたかもしれませんが,リスト1とリスト2を比較すると,オブジェクト指向のプログラムのほうが,(コードそのものは長くなったものの)コードがシンプルで読みやすくなっていると感じないでしょうか。手続きをデータと一体化した結果,一つひとつのコードがシンプルになったわけです。protected制限の場合もクラスの外部からは利用できません。ただし,継承したクラスからは利用できます。
カプセル化をC++言語で実装する
続いて,オブジェクト指向の三本柱をC++ではどう実装するのか解説していきましょう。まずはカプセル化です。
C++言語では,アクセス制限子にはpublicのほかにprivateとprotectedがあります。private制限をかけたメンバーにはクラスの中からしかアクセスできません。私的なメンバー変数,メンバー関数となるわけです。protected制限の場合もクラスの外部からは利用できません。ただし,継承したクラスからは利用できます。
例えばリスト2のプログラムの場合,入荷数はオブジェクト生成時に決まっており,通常は後で変更されることはありません。ですが,publicなメンバー変数にはプログラムのどこからでもアクセスできます。そこで,このような場合はリスト3のようにinamountメンバー変数をprivate制限にしてみます。こうすればコンパイル・エラーになり,不正を事前に防げます。
 リスト3●メンバー変数をprivateにする
リスト3●メンバー変数をprivateにする
カプセル化の対象はメンバー変数だけではありません。メンバー関数も「私的」にすることができます。getsaleメンバー関数はdispメンバー関数の中からしか呼ばれないとしたら,リスト4のようにprivateとして定義すればよいのです。これでクラスの中でしかgetsaleメンバー関数を呼び出すことができなくなります。
 リスト4●メンバー関数もprivateにできる
リスト4●メンバー関数もprivateにできる
クラスを利用するプログラマの目的は,クラスを利用してより効率的にプログラムを作成することです。ですから,呼び出すべきメンバー関数だけを公開して,知る必要のないメンバー関数を非公開にしておくほうが,より効率的にプログラミングを進めることができるはずです。
C++言語で継承を体験する
今度は継承を取り上げましょう。もう一度コンビニの店長に戻って,すべての商品の管理について考えてみます。まず,真っ先に思いつくのは,商品をすべて管理するには,汎用的な商品クラスを作成して,商品クラスを親クラスとする子クラスを商品の種別ごとに作ることでしょう(図8)。
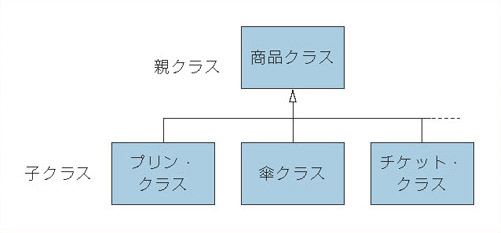 図8●商品クラスを考える
図8●商品クラスを考える
商品クラスを親クラスとして継承し,個々の商品のクラスを作っていけば,共通部分のプログラミングは1回で済ませることができます。そこで,個々の商品の特徴的な部分だけを子クラスに定義していきます。
リスト5を見てください*12-9。まず,親クラスであるGoodsクラスの定義の部分に注目してみましょう(1)。リスト2にあった,賞味期限を意味するlimitdateメンバーは,親クラスのメンバーからは外しています。これは,賞味期限のある商品とない商品が存在するからです。実際には,子クラスであるPuddingクラスで宣言します*12-10。メンバー関数のdispはどうでしょう。子クラスでのオーバーライド(再定義)を可能にするために,virtualキーワードを付けて仮想関数にしています*12-11。また,リスト4ではprivateなメンバーだったinamount,getsale( )を,protected制限に変更しています。これは子クラスでinamount,getsale( )を利用できるようにするためです。
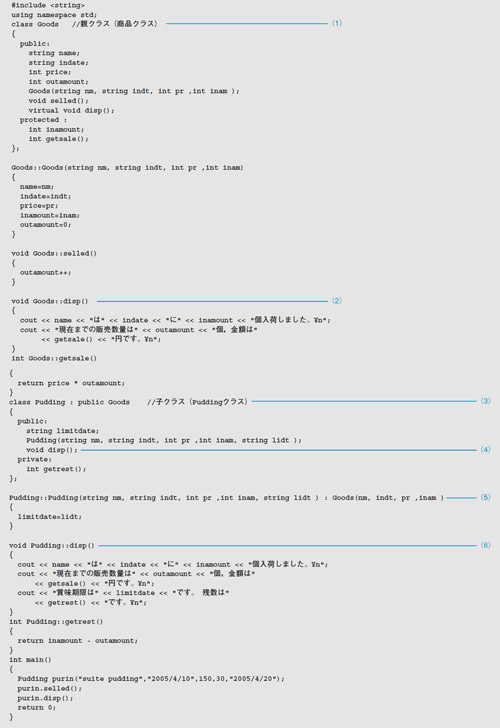 リスト5●継承を取り入れたプログラム
リスト5●継承を取り入れたプログラム
(3)の「class Pudding : public Goods」が,Goodsクラスを継承したPuddingクラスの宣言です。メンバー変数limitdateやメンバー関数getrest( )が子クラス独自の機能追加で,dispメンバー関数をオーバーライドしています(4)。
わかりにくいのは,(5)のコンストラクタでしょう。子クラスから呼び出す親クラスのコンストラクタを,「:」に続けて指定しています。(6)のオーバーライドしたdisp関数で,賞味期限と残数の表示を行っています。以上,リスト5を実行すると図9のようになります。
 図9●リスト5を実行したところ
図9●リスト5を実行したところ
このように商品クラスをベースにして,チケット・クラスは○○○を追加して扱うとか,卵クラスは□□□を上書きする…と継承を行っていけば効率的な開発ができます*12-12。
多態性(ポリモーフィズム)を理解する
最後に多態性(ポリモーフィズム)をプログラムしてみましょう。前述のように多態性は引数の数や型が異なる同一名のメソッドを複数作るオーバーロード(多重定義)と,親クラスで定義されているメソッドを,サブクラスにおいて同じ名前で定義し直すオーバーライド(再定義)で実現できます。
オーバーロード(多重定義)は,メンバー関数が関数名と引数で識別されるという仕様を利用したもので,引数をとらない関数,引数を一つとる関数,二つとる関数…と同名のメンバー関数を複数定義しておき,実行時には引数の数や型によって適当なメンバー関数が呼び出されるという仕組みです。これは便利でかつ理解しやすい仕様ですね。
もう一方のオーバーライド(再定義)は,少々理解しにくい面があります。同じ構造体同士なら,構造体型変数を代入できるという説明を覚えていますか? メンバー単位に代入しなくても構造体型変数でまとめて代入できるので便利でしたよね。クラスも同様なのです。同じクラスのインスタンス同士なら代入できます。それに加えて,C++には子クラスのインスタンスを親クラスに代入できるという特徴的な仕様があります。
これを一歩進めると,親クラスへのポインタに子クラスへのポインタが代入できることになります。動物の例でいうと,親クラス型のオブジェクトへのポインタ配列を作り,猫型オブジェクトへのポインタや犬型オブジェクトへのポインタを代入することが可能なのです。
ポインタが指すオブジェクトに「鳴け」とメッセージを渡すとポインタが猫型オブジェクトを指していたら「ニャン」と鳴き,犬ならば「ワン」と鳴くという「同じ指示に対して,様々な対応をする」という多態性がプログラミングできます。
では,コンビニの例で考えてみましょう。一つ売れると決まった額が慈善団体へ寄付されるというビスケットが新商品として入荷してきたとします。この商品の一個当たりの寄付額を管理し,いくら寄付されたかを表示したいとしましょう。
そこで,リスト5に追加したのがリスト6のクラスです。また,main関数は,親クラス,Puddingクラス,Charityクラスのインスタンスを作成してそれぞれのアドレスを親クラス型のポインタ配列に代入し,ポインタで各クラスのメンバー関数を呼び出すようにしました(リスト7)*12-13。このコードで実行すると,図10のようにそれぞれのオブジェクトのdispメンバー関数が実行されていることがわかります。C++言語ではこのようにして多態性を実現するのです。
 リスト6●新商品に対応して新しく追加するクラス
リスト6●新商品に対応して新しく追加するクラス
 リスト7●リスト6を使ったmain関数のコード
リスト7●リスト6を使ったmain関数のコード
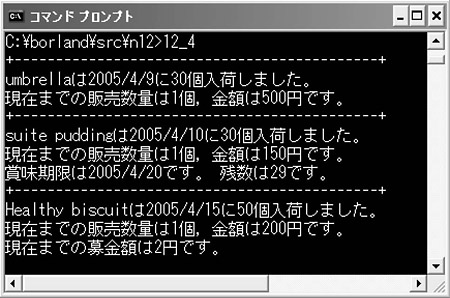 図10●リスト6,7の変更で実行したところ
図10●リスト6,7の変更で実行したところ
最後にひとこと
最終回だというのに,駆け足の解説になってしまいましたがいかがだったでしょうか。C言語を勉強した皆さんなら,C++を学習する基礎は身に付いています。なにせC++はCに1をインクリメントしただけの言語なのですから。ぜひこの先も,ご自分でC++言語の勉強を続けてください。
*1-1 母国語は機械語(マシン語) 英語と日本語の差ほどではないのですが,コンピュータやOSによって,マシン語にも違いがあります。例えば,Windows用のマシン語プログラムをUNIXマシンに持っていっても,そのまま実行させることはできません。
*1-2 マシン語プログラムを16進数で 2進数は,1桁で0と1の2値を表現できますが,マシン語などのダンプ表示に2進数を使うと,0と1がずらずらと並んでわかりにくくなります。そこで一般には2進数となじみのよい16進数で表記します。16進数1桁で2進数4桁を表現できます。
*1-3 自然言語 自然言語は,日本語や英語のように,人間が自然に使い出した言語のことです。
*1-4 バグ バグはコンピュータのプログラムに含まれる誤り,欠陥のことです。
*1-5 Java VM Java VMはJava Virtual Machine の略で,Javaの中間コードをマシン語に変換して実行するためのソフトウエアです。
*1-6 .NET Framework .NET Frameworkは,Microsoft .NET対応アプリケーションの動作環境です。.NET Framework用の中間コードにコンパイルされたコードを,.NETFrameworkがOSごとのマシン語に変換して動かします。JavaVMとの違いは特定の開発言語に依存しないことです。米Microsoftが提供する主要な開発言語であるVisual Basic/C++/C#などのほか,Borland Delphi 8でも.NETFramework対応のプログラムを作成できます。
*1-7 Windows 98におけるインストール Windows 98におけるインストールについては,日経ソフトウエアのWebサイトのWebスペシャルの情報などを参考にしてください。
*1-8 src srcはsource(ソース)の略で,一般にソース・プログラムを格納するフォルダ名として利用されます。
*2-1 この0と1の並び この0と1の2値を表す最小単位をビットと言います。ビットを八つたばねたものをバイトと呼びます。1バイトは8ビットです。
*2-2 ASCII(アスキー)コード ASCIIはAmerican Standard Code for Information Interchangeの略です。直訳すると,「情報交換のための米国の標準コード」となります。
*2-3 16進数では41 2進数と16進数は相性が良く,16進数1桁で2進数4桁を表すことができます。例えば,2進数8桁の1000001は,前半の0100が16進数で4,後半の0001が1なので16進数で41と表せます。
*2-4 NULやSOHなどの制御文字 制御文字は,例えば改行やタブなど,文字以外で文字の画面表示を制御するのに必要なコードのことです。
*2-5 意味は上の行にコメント C言語で「/」と「/」で囲まれた部分はコメントとして扱われます。複数 行にわたるコメントを書くこともできます。コメントはプログラムの処理内容を他人にわかりやすく説明するためだけでなく,自分の考えを整理するためにも役立ちますので,積極的に書くようにすべきです。
*3-1 Borland C++ Compiler 5.5は,ボーランドが無償配布しているC/C++のコンパイラです。
*3-2 エドガー・ダイクストラ(Edsger Wybe Dijkstra, 1930年―2002年)はコンピュータ科学者で,最短経路を求めるダイクストラ法にも名前を残すアルゴリズムの研究者でもあります。
*3-3 printfは標準ライブラリに登録されている関数で,標準出力(画面)に文字を表示します。
*3-4 ただし,Visual Basic 6.0の後継であるVisual Basic .NETでは,C言語のように値渡しがデフォルトになりました。
*3-5 プログラムと同じフォルダに作成したヘッダー・ファイルをインクルードするには,標準ヘッダー・ファイルとは異なりダブルクォーテーションでファイル名を囲みます。
*4-1 変数を宣言と同時に初期化するクセをつければ,変数に初期値を与えずに使ってしまうというミスを防ぐことができます。
*4-2 ローカル変数であろうがグローバル変数であろうが,変数は使う前に,必ず宣言されていなければなりません。宣言せずに使おうとすれば,コンパイル・エラーになります。
*4-3 変換仕様%2dの2は出力する桁数(幅)を指定します。\tは,改行を表す\nと同じエスケープ・シーケンスでタブを意味します。変換仕様%2dで出力する桁数を指定したり,\tでタブを入れることで開始位置を合わせて見やすくしています。
*4-4 ++aのようにインクリメント演算子を前置しているので,各変数の値が変換仕様に展開されて表示される前に,変数値が1ずつアップされます。逆にa++と後置すると,0,1,2,3,4と表示されます。
*4-5 staticを付けていないローカル変数はauto(自動)変数です。通常は指定しませんが,auto int bのように宣言することもできます。
*5-1 scanf関数の第2引数に「&rtime1」などとアドレス演算子&を付けているのは,scanf関数が変数のアドレスを使う関数だからです。
*5-2 アルゴリズムの語源は9世紀のアラビアの数学者の名前で,元々は算法とか演算方法という意味だと言われています。
*5-3 合成数とは,素数の積で表すことができる数,つまり,素因数分解できる数のことです。
*5-4 %演算子は剰余を求めます。
*5-5 break文は,forループから抜け出します。